Java工程师面试题-Java语言-JVM
推荐先阅读:Java工程师面试题
JVM包含哪几部分?
参考答案
JVM 主要由四大部分组成:ClassLoader(类加载器),Runtime Data Area(运行时数据区,内存分区),Execution Engine(执行引擎),Native Interface(本地库接口),下图可以大致描述 JVM 的结构。

JVM 是执行 Java 程序的虚拟计算机系统,那我们来看看执行过程:首先需要准备好编译好的 Java 字节码文件(即class文件),计算机要运行程序需要先通过一定方式(类加载器)将 class 文件加载到内存中(运行时数据区),但是字节码文件是JVM定义的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解释器(执行引擎)将字节码翻译成特定的操作系统指令集交给 CPU 去执行,这个过程中会需要调用到一些不同语言为 Java 提供的接口(例如驱动、地图制作等),这就用到了本地 Native 接口(本地库接口)。
- ClassLoader:负责加载字节码文件即 class 文件,class 文件在文件开头有特定的文件标示,并且 ClassLoader 只负责class 文件的加载,至于它是否可以运行,则由 Execution Engine 决定。
- Runtime Data Area:是存放数据的,分为五部分:Stack(虚拟机栈),Heap(堆),Method Area(方法区),PC Register(程序计数器),Native Method Stack(本地方法栈)。几乎所有的关于 Java 内存方面的问题,都是集中在这块。
- Execution Engine:执行引擎,也叫 Interpreter。Class 文件被加载后,会把指令和数据信息放入内存中,Execution Engine 则负责把这些命令解释给操作系统,即将 JVM 指令集翻译为操作系统指令集。
- Native Interface:负责调用本地接口的。他的作用是调用不同语言的接口给 JAVA 用,他会在 Native Method Stack 中记录对应的本地方法,然后调用该方法时就通过 Execution Engine 加载对应的本地 lib。原本多用于一些专业领域,如JAVA驱动,地图制作引擎等,现在关于这种本地方法接口的调用已经被类似于Socket通信,WebService等方式取代。
JVM是如何运行的?
参考答案
JVM的启动过程分为如下四个步骤:
JVM的装入环境和配置
java.exe负责查找JRE,并且它会按照如下的顺序来选择JRE:
- 自己目录下的JRE;
- 父级目录下的JRE;
- 查注册中注册的JRE。
装载JVM
通过第一步找到JVM的路径后,Java.exe通过LoadJavaVM来装入JVM文件。LoadLibrary装载JVM动态连接库,然后把JVM中的到处函数JNI_CreateJavaVM和JNI_GetDefaultJavaVMIntArgs 挂接到InvocationFunction 变量的CreateJavaVM和GetDafaultJavaVMInitArgs 函数指针变量上。JVM的装载工作完成。
初始化JVM,获得本地调用接口
调用InvocationFunction -> CreateJavaVM,也就是JVM中JNI_CreateJavaVM方法获得JNIEnv结构的实例。
运行Java程序
JVM运行Java程序的方式有两种:jar包 与 class。
运行jar 的时候,java.exe调用GetMainClassName函数,该函数先获得JNIEnv实例然后调用JarFileJNIEnv类中getManifest(),从其返回的Manifest对象中取getAttrebutes(“Main-Class”)的值,即jar 包中文件:META-INF/MANIFEST.MF指定的Main-Class的主类名作为运行的主类。之后main函数会调用Java.c中LoadClass方法装载该主类(使用JNIEnv实例的FindClass)。
运行Class的时候,main函数直接调用Java.c中的LoadClass方法装载该类。
Java程序是怎么运行的?
参考答案
概括来说,写好的 Java 源代码文件经过 Java 编译器编译成字节码文件后,通过类加载器加载到内存中,才能被实例化,然后到 Java 虚拟机中解释执行,最后通过操作系统操作 CPU 执行获取结果。如下图:

本地方法栈有什么用?
参考答案
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
《Java虚拟机规范》对本地方法栈中方法使用的语言、使用方式与数据结构并没有任何强制规定,因此具体的虚拟机可以根据需要自由实现它,甚至有的Java虚拟机(譬如Hot-Spot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈也会在栈深度溢出或者栈扩展失败时分别抛出StackOverflowError和OutOfMemoryError异常。
没有程序计数器会怎么样?
参考答案
没有程序计数器,Java程序中的流程控制将无法得到正确的控制,多线程也无法正确的轮换。
扩展阅读
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在Java虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是本地(Native)方法,这个计数器值则应为空(Undefined)。此内存区域是唯一一个在《Java虚拟机规范》中没有规定任何OutOfMemoryError情况的区域。
说一说Java的内存分布情况
参考答案
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而一直存在,有些区域则是依赖用户线程的启动和结束而建立和销毁。根据《Java虚拟机规范》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域。

程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在Java虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是本地(Native)方法,这个计数器值则应为空(Undefined)。此内存区域是唯一一个在《Java虚拟机规范》中没有规定任何OutOfMemoryError情况的区域。
Java虚拟机栈
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stack)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧[插图](Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
在《Java虚拟机规范》中,对这个内存区域规定了两类异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果Java虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError异常。
本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
《Java虚拟机规范》对本地方法栈中方法使用的语言、使用方式与数据结构并没有任何强制规定,因此具体的虚拟机可以根据需要自由实现它,甚至有的Java虚拟机(譬如Hot-Spot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈也会在栈深度溢出或者栈扩展失败时分别抛出StackOverflowError和OutOfMemoryError异常。
Java堆
对于Java应用程序来说,Java堆(Java Heap)是虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,Java世界里“几乎”所有的对象实例都在这里分配内存。在《Java虚拟机规范》中对Java堆的描述是:“所有的对象实例以及数组都应当在堆上分配”,而这里笔者写的“几乎”是指从实现角度来看,随着Java语言的发展,现在已经能看到些许迹象表明日后可能出现值类型的支持,即使只考虑现在,由于即时编译技术的进步,尤其是逃逸分析技术的日渐强大,栈上分配、标量替换优化手段已经导致一些微妙的变化悄然发生,所以说Java对象实例都分配在堆上也渐渐变得不是那么绝对了。
根据《Java虚拟机规范》的规定,Java堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的,这点就像我们用磁盘空间去存储文件一样,并不要求每个文件都连续存放。但对于大对象(典型的如数组对象),多数虚拟机实现出于实现简单、存储高效的考虑,很可能会要求连续的内存空间。
Java堆既可以被实现成固定大小的,也可以是可扩展的,不过当前主流的Java虚拟机都是按照可扩展来实现的(通过参数-Xmx和-Xms设定)。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。
方法区
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。虽然《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫作“非堆”(Non-Heap),目的是与Java堆区分开来。
根据《Java虚拟机规范》的规定,如果方法区无法满足新的内存分配需求时,将抛出OutOfMemoryError异常。
运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出OutOfMemoryError异常。
直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现。
显然,本机直接内存的分配不会受到Java堆大小的限制,但是,既然是内存,则肯定还是会受到本机总内存(包括物理内存、SWAP分区或者分页文件)大小以及处理器寻址空间的限制,一般服务器管理员配置虚拟机参数时,会根据实际内存去设置-Xmx等参数信息,但经常忽略掉直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现OutOfMemoryError异常。
类存放在哪里?
参考答案
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。虽然《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫作“非堆”(Non-Heap),目的是与Java堆区分开来。
局部变量存放在哪里?
参考答案
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stack)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种Java虚拟机基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)。
介绍一下Java代码的编译过程
参考答案
从Javac代码的总体结构来看,编译过程大致可以分为1个准备过程和3个处理过程,它们分别如下所示。
准备过程:初始化插入式注解处理器。
解析与填充符号表过程,包括:
- 词法、语法分析,将源代码的字符流转变为标记集合,构造出抽象语法树。
- 填充符号表,产生符号地址和符号信息。
插入式注解处理器的注解处理过程:
在Javac源码中,插入式注解处理器的初始化过程是在initPorcessAnnotations()方法中完成的,而它的执行过程则是在processAnnotations()方法中完成。这个方法会判断是否还有新的注解处理器需要执行,如果有的话,通过JavacProcessing-Environment类的doProcessing()方法来生成一个新的JavaCompiler对象,对编译的后续步骤进行处理。
分析与字节码生成过程,包括:
- 标注检查,对语法的静态信息进行检查。
- 数据流及控制流分析,对程序动态运行过程进行检查。
- 解语法糖,将简化代码编写的语法糖还原为原有的形式。
- 字节码生成,将前面各个步骤所生成的信息转化成字节码。
上述3个处理过程里,执行插入式注解时又可能会产生新的符号,如果有新的符号产生,就必须转回到之前的解析、填充符号表的过程中重新处理这些新符号,从总体来看,三者之间的关系与交互顺序如图所示。

介绍一下类加载的过程
参考答案
一个类型从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)七个阶段,其中验证、准备、解析三个部分统称为连接(Linking)。这七个阶段的发生顺序如下图所示。
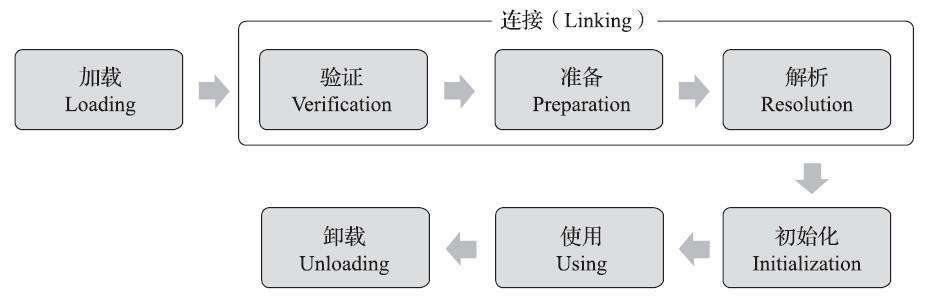
在上述七个阶段中,包括了类加载的全过程,即加载、验证、准备、解析和初始化这五个阶段。
一、加载
“加载”(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段,在加载阶段,Java虚拟机需要完成以下三件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
加载阶段结束后,Java虚拟机外部的二进制字节流就按照虚拟机所设定的格式存储在方法区之中了,方法区中的数据存储格式完全由虚拟机实现自行定义,《Java虚拟机规范》未规定此区域的具体数据结构。类型数据妥善安置在方法区之后,会在Java堆内存中实例化一个java.lang.Class类的对象,这个对象将作为程序访问方法区中的类型数据的外部接口。
二、验证
验证是连接阶段的第一步,这一阶段的目的是确保Class文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。验证阶段大致上会完成下面四个阶段的检验动作:文件格式验证、元数据验证、字节码验证和符号引用验证。
文件格式验证:
第一阶段要验证字节流是否符合Class文件格式的规范,并且能被当前版本的虚拟机处理。
元数据验证:
第二阶段是对字节码描述的信息进行语义分析,以保证其描述的信息符合《Java语言规范》的要求。
字节码验证:
第三阶段是通过数据流分析和控制流分析,确定程序语义是合法的、符合逻辑的。
符号引用验证:
符号引用验证可以看作是对类自身以外(常量池中的各种符号引用)的各类信息进行匹配性校验,通俗来说就是,该类是否缺少或者被禁止访问它依赖的某些外部类、方法、字段等资源。
三、准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。从概念上讲,这些变量所使用的内存都应当在方法区中进行分配,但必须注意到方法区本身是一个逻辑上的区域,在JDK7及之前,HotSpot使用永久代来实现方法区时,实现是完全符合这种逻辑概念的。而在JDK 8及之后,类变量则会随着Class对象一起存放在Java堆中,这时候“类变量在方法区”就完全是一种对逻辑概念的表述了。
四、解析
解析阶段是Java虚拟机将常量池内的符号引用替换为直接引用的过程,符号引用在Class文件中以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等类型的常量出现,那解析阶段中所说的直接引用与符号引用又有什么关联呢?
符号引用(Symbolic References):符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定是已经加载到虚拟机内存当中的内容。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须都是一致的,因为符号引用的字面量形式明确定义在《Java虚拟机规范》的Class文件格式中。
直接引用(Direct References):直接引用是可以直接指向目标的指针、相对偏移量或者是一个能间接定位到目标的句柄。直接引用是和虚拟机实现的内存布局直接相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经在虚拟机的内存中存在。
五、初始化
类的初始化阶段是类加载过程的最后一个步骤,之前介绍的几个类加载的动作里,除了在加载阶段用户应用程序可以通过自定义类加载器的方式局部参与外,其余动作都完全由Java虚拟机来主导控制。直到初始化阶段,Java虚拟机才真正开始执行类中编写的Java程序代码,将主导权移交给应用程序。
进行准备阶段时,变量已经赋过一次系统要求的初始零值,而在初始化阶段,则会根据程序员通过程序编码制定的主观计划去初始化类变量和其他资源。我们也可以从另外一种更直接的形式来表达:初始化阶段就是执行类构造器
介绍一下对象的实例化过程
参考答案
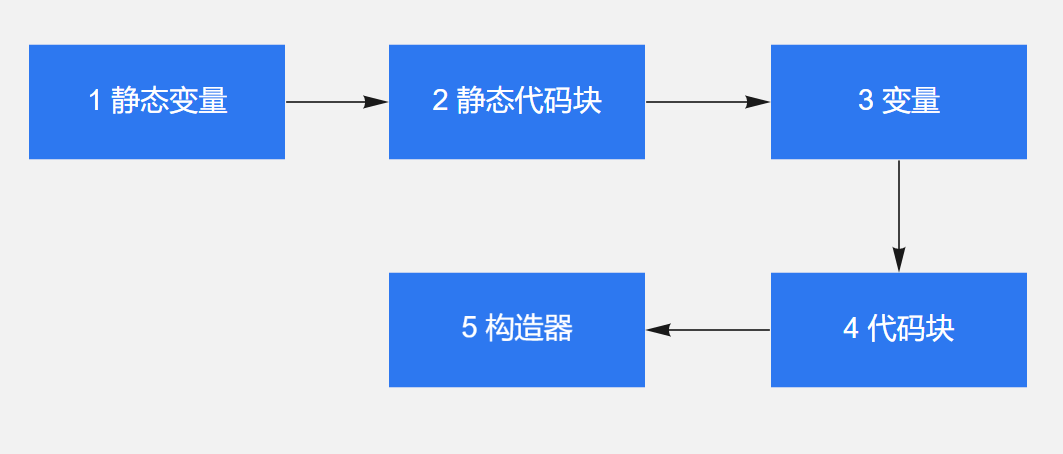
对象实例化过程,就是执行类构造函数对应在字节码文件中的
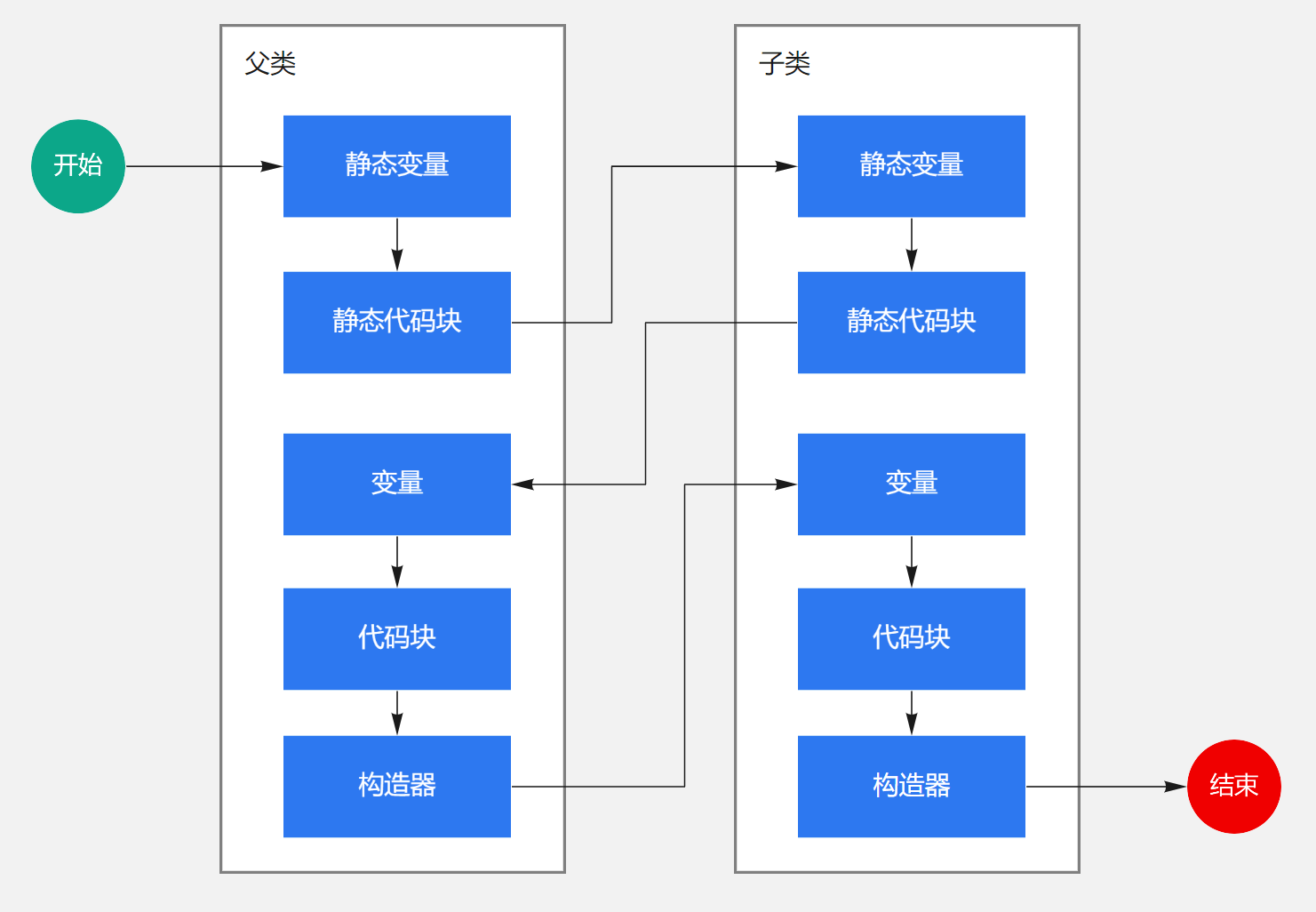
()方法可以重载多个,类有几个构造器就有几个 ()方法; ()方法中的代码执行顺序为:父类变量初始化、父类代码块、父类构造器、子类变量初始化、子类代码块、子类构造器。
静态变量、静态代码块、普通变量、普通代码块、构造器的执行顺序如下图:
具有父类的子类的实例化顺序如下:
扩展阅读
Java是一门面向对象的编程语言,Java程序运行过程中无时无刻都有对象被创建出来。在语言层面上,创建对象通常(例外:复制、反序列化)仅仅是一个new关键字而已,而在虚拟机中,对象(文中讨论的对象限于普通Java对象,不包括数组和Class对象等)的创建又是怎样一个过程呢?
当Java虚拟机遇到一条字节码new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务实际上便等同于把一块确定大小的内存块从Java堆中划分出来。假设Java堆中内存是绝对规整的,所有被使用过的内存都被放在一边,空闲的内存被放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那个指针向空闲空间方向挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”(Bump The Pointer)。但如果Java堆中的内存并不是规整的,已被使用的内存和空闲的内存相互交错在一起,那就没有办法简单地进行指针碰撞了,虚拟机就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为“空闲列表”(Free List)。选择哪种分配方式由Java堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有空间压缩整理(Compact)的能力决定。因此,当使用Serial、ParNew等带压缩整理过程的收集器时,系统采用的分配算法是指针碰撞,既简单又高效;而当使用CMS这种基于清除(Sweep)算法的收集器时,理论上就只能采用较为复杂的空闲列表来分配内存。
除如何划分可用空间之外,还有另外一个需要考虑的问题:对象创建在虚拟机中是非常频繁的行为,即使仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。解决这个问题有两种可选方案:一种是对分配内存空间的动作进行同步处理——实际上虚拟机是采用CAS配上失败重试的方式保证更新操作的原子性;另外一种是把内存分配的动作按照线程划分在不同的空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),哪个线程要分配内存,就在哪个线程的本地缓冲区中分配,只有本地缓冲区用完了,分配新的缓存区时才需要同步锁定。虚拟机是否使用TLAB,可以通过-XX:+/-UseTLAB参数来设定。
内存分配完成之后,虚拟机必须将分配到的内存空间(但不包括对象头)都初始化为零值,如果使用了TLAB的话,这一项工作也可以提前至TLAB分配时顺便进行。这步操作保证了对象的实例字段在Java代码中可以不赋初始值就直接使用,使程序能访问到这些字段的数据类型所对应的零值。
接下来,Java虚拟机还要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码(实际上对象的哈希码会延后到真正调用Object::hashCode()方法时才计算)、对象的GC分代年龄等信息。这些信息存放在对象的对象头(Object Header)之中。根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了。但是从Java程序的视角看来,对象创建才刚刚开始——构造函数,即Class文件中的
补充:简述对象创建方法
答:对象的创建方法主要是:new的过程
- 进行类加载检查。当遇到一个new指令,首先检查能否在方法区的常量池中能否定位到这个类的符号引用,并且检查类有没有进行加载、解析和初始化;
- 分配空间。有两种常见的分配方式,一是指针碰撞,二是空闲列表,分别针对连续分配内存和不连续的,有空隙的,取决于虚拟机是否会压缩整理。内存分配的大小是在类加载完成之后就已经确定的,但是分配的时候修改指针的指向位置应该是线程安全的(栈上的Reference),第一种方式就保证原子性;第二种是给每个线程分配自己的一小块内存,成为本地线程分配缓冲(TLAB),每个线程在自己的TLAB是哪个分配。
- 初始化。将分配的内存初始化为0值。
- 基本设置。进行基本的设置,确定这个对象是哪个类的实例,对象的HASH码,对象的年龄等等。
元空间在栈内还是栈外?
参考答案
在栈外,元空间占用的是本地内存。
扩展阅读
许多Java程序员都习惯在HotSpot虚拟机上开发、部署程序,很多人都更愿意把方法区称呼为“永久代“,或将两者混为一谈。本质上这两者并不是等价的,因为仅仅是当时的HotSpot虚拟机设计团队选择把收集器的分代设计扩展至方法区,或者说使用永久代来实现方法区而已,这样使得HotSpot的垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。但是对于其他虚拟机实现,譬如BEAJRockit、IBM J9等来说,是不存在永久代的概念的。原则上如何实现方法区属于虚拟机实现细节,不受《Java虚拟机规范》管束,并不要求统一。
现在回头来看,当年使用永久代来实现方法区的决定并不是一个好主意,这种设计导致了Java应用更容易遇到内存溢出的问题(永久代有-XX:MaxPermSize的上限,即使不设置也有默认大小,而J9和JRockit只要没有触碰到进程可用内存的上限,例如32位系统中的4GB限制,就不会出问题),而且有极少数方法(例如String::intern())会因永久代的原因而导致不同虚拟机下有不同的表现。
当Oracle收购BEA获得了JRockit的所有权后,准备把JRockit中的优秀功能,譬如Java Mission Control管理工具,移植到HotSpot虚拟机时,但因为两者对方法区实现的差异而面临诸多困难。考虑到HotSpot未来的发展,在JDK 6的时候HotSpot开发团队就有放弃永久代,逐步改为采用本地内存(Native Memory)来实现方法区的计划了,到了JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出,而到了JDK 8,终于完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Meta-space)来代替,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中。
谈谈JVM的类加载器,以及双亲委派模型
参考答案
一、类加载器
Java虚拟机设计团队有意把类加载阶段中的“通过一个类的全限定名来获取描述该类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需的类。实现这个动作的代码被称为“类加载器”(Class Loader)。
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远超类加载阶段。对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
二、双亲委派模型
自JDK1.2以来,Java一直保持着三层类加载器、双亲委派的类加载架构。对于这个时期的Java应用,绝大多数Java程序都会使用到以下3个系统提供的类加载器来进行加载。
- 启动类加载器(Bootstrap Class Loader):这个类加载器负责加载存放在
\lib目录,或者被-Xbootclasspath参数所指定的路径中存放的,而且是Java虚拟机能够识别的(按照文件名识别,如rt.jar、tools.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机的内存中。启动类加载器无法被Java程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给引导类加载器去处理,那直接使用null代替即可。 - 扩展类加载器(Extension Class Loader):这个类加载器是在类sun.misc.Launcher$ExtClassLoader中以Java代码的形式实现的。它负责加载
\lib\ext目录中,或者被java.ext.dirs系统变量所指定的路径中所有的类库。根据“扩展类加载器”这个名称,就可以推断出这是一种Java系统类库的扩展机制,JDK的开发团队允许用户将具有通用性的类库放置在ext目录里以扩展Java SE的功能,在JDK 9之后,这种扩展机制被模块化带来的天然的扩展能力所取代。由于扩展类加载器是由Java代码实现的,开发者可以直接在程序中使用扩展类加载器来加载Class文件。 - 应用程序类加载器(Application Class Loader):这个类加载器由sun.misc.Launcher$AppClassLoader来实现。由于应用程序类加载器是ClassLoader类中的getSystem-ClassLoader()方法的返回值,所以有些场合中也称它为“系统类加载器”。它负责加载用户类路径(ClassPath)上所有的类库,开发者同样可以直接在代码中使用这个类加载器。如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
这些类加载器之间的协作关系“通常”会如下图所示,图中展示的各种类加载器之间的层次关系被称为类加载器的“双亲委派模型(Parents Delegation Model)”。双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。不过这里类加载器之间的父子关系一般不是以继承(Inheritance)的关系来实现的,而是通常使用组合(Composition)关系来复用父加载器的代码。

双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
使用双亲委派模型来组织类加载器之间的关系,一个显而易见的好处就是Java中的类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都能够保证是同一个类。反之,如果没有使用双亲委派模型,都由各个类加载器自行去加载的话,如果用户自己也编写了一个名为java.lang.Object的类,并放在程序的ClassPath中,那系统中就会出现多个不同的Object类,Java类型体系中最基础的行为也就无从保证,应用程序将会变得一片混乱。
扩展阅读
双亲委派模型对于保证Java程序的稳定运作极为重要,但它的实现却异常简单,用以实现双亲委派的代码只有短短十余行,全部集中在java.lang.ClassLoader的loadClass()方法之中。
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { |
这段代码的逻辑清晰易懂:先检查请求加载的类型是否已经被加载过,若没有则调用父加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。假如父类加载器加载失败,抛出ClassNotFoundException异常的话,才调用自己的findClass()方法尝试进行加载。
补充:类加载器双亲委派模型机制
当一个类收到了类加载请求时,不会自己先去加载这个类,而是将其委派给父类,由父类去加载,如果此时父类不能加载,反馈给子类,由子类去完成类的加载。

双亲委派模型的好处
- 主要是为了安全性,避免用户自己编写的类动态替换 java的一些核心类,比如 String。
- 同时也避免了类的重复加载,因为 JVM中区分不同类,不仅仅是根据类名,相同的 class文件被不 同的 ClassLoader加载就是不同的两个类
双亲委派机制会被破坏吗?
参考答案
双亲委派模型并不是一个具有强制性约束的模型,而是Java设计者推荐给开发者们的类加载器实现方式。在Java的世界中大部分的类加载器都遵循这个模型,但也有例外的情况,直到Java模块化出现为止,双亲委派模型主要出现过3次较大规模“被破坏”的情况。
双亲委派模型的第一次“被破坏”其实发生在双亲委派模型出现之前——即JDK 1.2面世以前的“远古”时代。由于双亲委派模型在JDK 1.2之后才被引入,但是类加载器的概念和抽象类java.lang.ClassLoader则在Java的第一个版本中就已经存在,面对已经存在的用户自定义类加载器的代码,Java设计者们引入双亲委派模型时不得不做出一些妥协,为了兼容这些已有代码,无法再以技术手段避免loadClass()被子类覆盖的可能性,只能在JDK 1.2之后的java.lang.ClassLoader中添加一个新的protected方法findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在loadClass()中编写代码。双亲委派的具体逻辑就实现在这里面,按照loadClass()方法的逻辑,如果父类加载失败,会自动调用自己的findClass()方法来完成加载,这样既不影响用户按照自己的意愿去加载类,又可以保证新写出来的类加载器是符合双亲委派规则的。
双亲委派模型的第二次“被破坏”是由这个模型自身的缺陷导致的,双亲委派很好地解决了各个类加载器协作时基础类型的一致性问题(越基础的类由越上层的加载器进行加载),基础类型之所以被称为“基础”,是因为它们总是作为被用户代码继承、调用的API存在,但程序设计往往没有绝对不变的完美规则,如果有基础类型又要调用回用户的代码,那该怎么办呢?
这并非是不可能出现的事情,一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器来完成加载(在JDK 1.3时加入到rt.jar的),肯定属于Java中很基础的类型了。但JNDI存在的目的就是对资源进行查找和集中管理,它需要调用由其他厂商实现并部署在应用程序的ClassPath下的JNDI服务提供者接口(Service Provider Interface,SPI)的代码,现在问题来了,启动类加载器是绝不可能认识、加载这些代码的,那该怎么办?
为了解决这个困境,Java的设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContext-ClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
有了线程上下文类加载器,程序就可以做一些“舞弊”的事情了。JNDI服务使用这个线程上下文类加载器去加载所需的SPI服务代码,这是一种父类加载器去请求子类加载器完成类加载的行为,这种行为实际上是打通了双亲委派模型的层次结构来逆向使用类加载器,已经违背了双亲委派模型的一般性原则,但也是无可奈何的事情。Java中涉及SPI的加载基本上都采用这种方式来完成,例如JNDI、JDBC、JCE、JAXB和JBI等。不过,当SPI的服务提供者多于一个的时候,代码就只能根据具体提供者的类型来硬编码判断,为了消除这种极不优雅的实现方式,在JDK 6时,JDK提供了java.util.ServiceLoader类,以META-INF/services中的配置信息,辅以责任链模式,这才算是给SPI的加载提供了一种相对合理的解决方案。
双亲委派模型的第三次“被破坏”是由于用户对程序动态性的追求而导致的,这里所说的“动态性”指的是一些非常“热”门的名词:代码热替换(HotSwap)、模块热部署(Hot Deployment)等。说白了就是希望Java应用程序能像我们的电脑外设那样,接上鼠标、U盘,不用重启机器就能立即使用,鼠标有问题或要升级就换个鼠标,不用关机也不用重启。对于个人电脑来说,重启一次其实没有什么大不了的,但对于一些生产系统来说,关机重启一次可能就要被列为生产事故,这种情况下热部署就对软件开发者,尤其是大型系统或企业级软件开发者具有很大的吸引力。
早在2008年,在Java社区关于模块化规范的第一场战役里,由Sun/Oracle公司所提出的JSR-294、JSR-277规范提案就曾败给以IBM公司主导的JSR-291(即OSGi R4.2)提案。尽管Sun/Oracle并不甘心就此失去Java模块化的主导权,随即又再拿出Jigsaw项目迎战,但此时OSGi已经站稳脚跟,成为业界“事实上”的Java模块化标准。曾经在很长一段时间内,IBM凭借着OSGi广泛应用基础让Jigsaw吃尽苦头,其影响一直持续到Jigsaw随JDK 9面世才算告一段落。而且即使Jigsaw现在已经是Java的标准功能了,它仍需小心翼翼地避开OSGi运行期动态热部署上的优势,仅局限于静态地解决模块间封装隔离和访问控制的问题,现在我们先来简单看一看OSGi是如何通过类加载器实现热部署的。
OSGi实现模块化热部署的关键是它自定义的类加载器机制的实现,每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi环境下,类加载器不再双亲委派模型推荐的树状结构,而是进一步发展为更加复杂的网状结构,当收到类加载请求时,OSGi将按照下面的顺序进行类搜索:
- 将以java.*开头的类,委派给父类加载器加载。
- 否则,将委派列表名单内的类,委派给父类加载器加载。
- 否则,将Import列表中的类,委派给Export这个类的Bundle的类加载器加载。
- 否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。
- 否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载。
- 否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。
- 否则,类查找失败。
上面的查找顺序中只有开头两点仍然符合双亲委派模型的原则,其余的类查找都是在平级的类加载器中进行的。
介绍一下Java的垃圾回收机制
参考答案
一、哪些内存需要回收
在Java内存运行时区域的各个部分中,堆和方法区这两个区域则有着很显著的不确定性:一个接口的多个实现类需要的内存可能会不一样,一个方法所执行的不同条件分支所需要的内存也可能不一样,只有处于运行期间,我们才能知道程序究竟会创建哪些对象,创建多少个对象,这部分内存的分配和回收是动态的。垃圾收集器所关注的正是这部分内存该如何管理,我们平时所说的内存分配与回收也仅仅特指这一部分内存。
二、怎么定义垃圾
引用计数算法:
在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。
但是,在Java领域,至少主流的Java虚拟机里面都没有选用引用计数算法来管理内存,主要原因是,这个看似简单的算法有很多例外情况要考虑,必须要配合大量额外处理才能保证正确地工作,譬如单纯的引用计数就很难解决对象之间相互循环引用的问题。
举个简单的例子:对象objA和objB都有字段instance,赋值令objA.instance=objB及objB.instance=objA,除此之外,这两个对象再无任何引用,实际上这两个对象已经不可能再被访问,但是它们因为互相引用着对方,导致它们的引用计数都不为零,引用计数算法也就无法回收它们。
可达性分析算法:
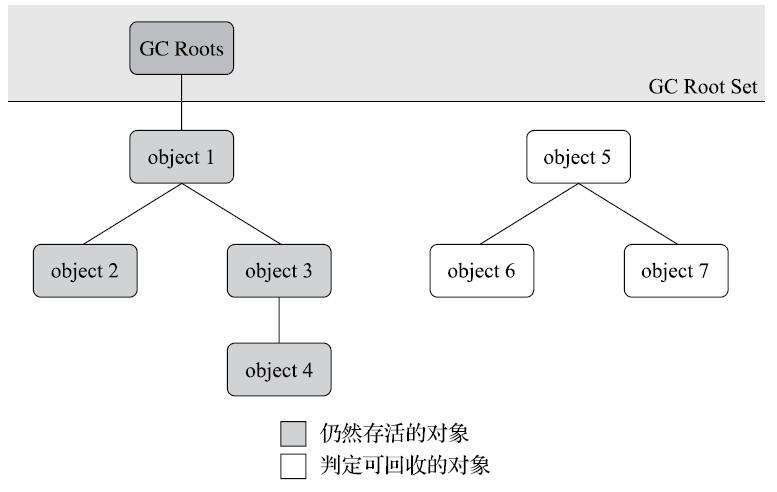
当前主流的商用程序语言的内存管理子系统,都是通过可达性分析(Reachability Analysis)算法来判定对象是否存活的。这个算法的基本思路就是通过一系列称为“GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”(Reference Chain),如果某个对象到GC Roots间没有任何引用链相连,或者用图论的话来说就是从GC Roots到这个对象不可达时,则证明此对象是不可能再被使用的。
如下图所示,对象object 5、object 6、object 7虽然互有关联,但是它们到GC Roots是不可达的,因此它们将会被判定为可回收的对象。
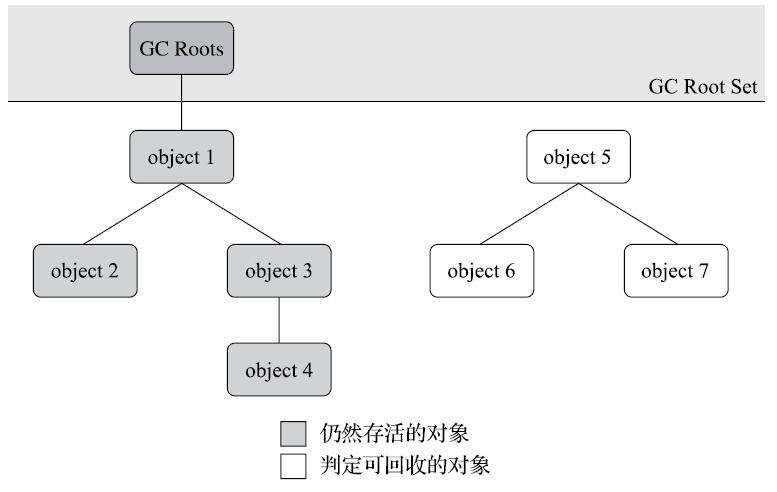
在Java技术体系里面,固定可作为GC Roots的对象包括以下几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。
- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
- 所有被同步锁(synchronized关键字)持有的对象。
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
回收方法区:
方法区的垃圾收集主要回收两部分内容:废弃的常量和不再使用的类型。回收废弃常量与回收Java堆中的对象非常类似。举个常量池中字面量回收的例子,假如一个字符串“java”曾经进入常量池中,但是当前系统又没有任何一个字符串对象的值是“java”,换句话说,已经没有任何字符串对象引用常量池中的“java”常量,且虚拟机中也没有其他地方引用这个字面量。如果在这时发生内存回收,而且垃圾收集器判断确有必要的话,这个“java”常量就将会被系统清理出常量池。常量池中其他类(接口)、方法、字段的符号引用也与此类似。
判定一个常量是否“废弃”还是相对简单,而要判定一个类型是否属于“不再被使用的类”的条件就比较苛刻了。需要同时满足下面三个条件:
- 该类所有的实例都已经被回收,也就是Java堆中不存在该类及其任何派生子类的实例。
- 加载该类的类加载器已经被回收,这个条件除非是经过精心设计的可替换类加载器的场景,如OSGi、JSP的重加载等,否则通常是很难达成的。
- 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
三、怎么回收垃圾
分代收集理论:
当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集”(GenerationalCollection)的理论进行设计,分代收集名为理论,实质是一套符合大多数程序运行实际情况的经验法则,它建立在两个分代假说之上:
- 弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。
- 强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消亡。
这两个分代假说共同奠定了多款常用的垃圾收集器的一致的设计原则:收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄(年龄即对象熬过垃圾收集过程的次数)分配到不同的区域之中存储。显而易见,如果一个区域中大多数对象都是朝生夕灭,难以熬过垃圾收集过程的话,那么把它们集中放在一起,每次回收时只关注如何保留少量存活而不是去标记那些大量将要被回收的对象,就能以较低代价回收到大量的空间;如果剩下的都是难以消亡的对象,那把它们集中放在一块,虚拟机便可以使用较低的频率来回收这个区域,这就同时兼顾了垃圾收集的时间开销和内存的空间有效利用。
标记-清除算法:
最早出现也是最基础的垃圾收集算法是“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。
它的主要缺点有两个:第一个是执行效率不稳定,如果Java堆中包含大量对象,而且其中大部分是需要被回收的,这时必须进行大量标记和清除的动作,导致标记和清除两个过程的执行效率都随对象数量增长而降低;第二个是内存空间的碎片化问题,标记、清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致当以后在程序运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。标记-清除算法的执行过程如下图所示。
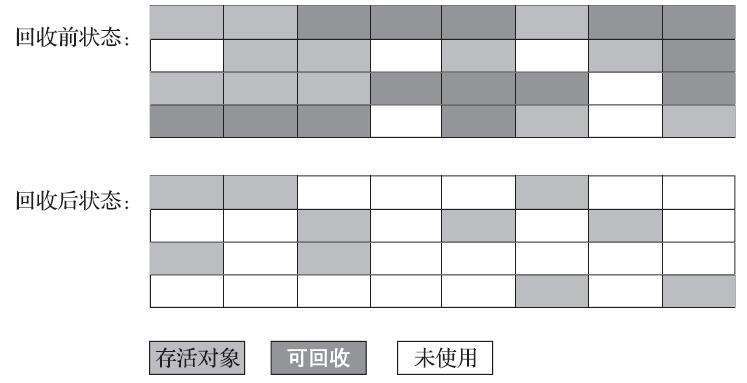
标记-复制算法:
为了解决标记-清除算法面对大量可回收对象时执行效率低的问题,1969年Fenichel提出了一种称为“半区复制”(Semispace Copying)的垃圾收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。如果内存中多数对象都是存活的,这种算法将会产生大量的内存间复制的开销,但对于多数对象都是可回收的情况,算法需要复制的就是占少数的存活对象,而且每次都是针对整个半区进行内存回收,分配内存时也就不用考虑有空间碎片的复杂情况,只要移动堆顶指针,按顺序分配即可。这样实现简单,运行高效,不过其缺陷也显而易见,这种复制回收算法的代价是将可用内存缩小为了原来的一半,空间浪费未免太多了一点。标记-复制算法的执行过程如下图所示。
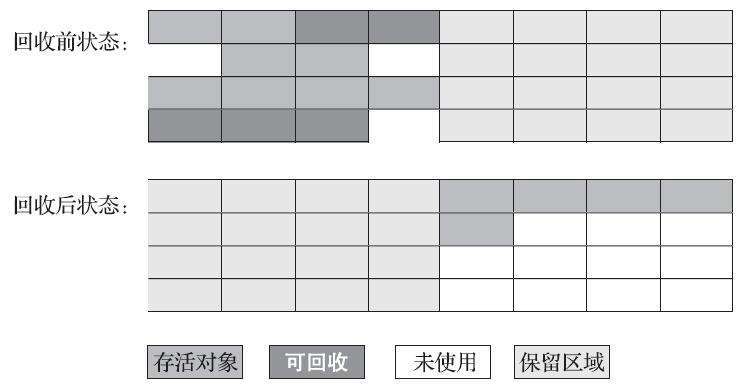
在1989年,Andrew Appel针对具备“朝生夕灭”特点的对象,提出了一种更优化的半区复制分代策略,现在称为“Appel式回收”。Appel式回收的具体做法是把新生代分为一块较大的Eden空间和两块较小的Survivor空间,每次分配内存只使用Eden和其中一块Survivor。发生垃圾搜集时,将Eden和Survivor中仍然存活的对象一次性复制到另外一块Survivor空间上,然后直接清理掉Eden和已用过的那块Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8∶1,也即每次新生代中可用内存空间为整个新生代容量的90%(Eden的80%加上一个Survivor的10%),只有一个Survivor空间,即10%的新生代是会被“浪费”的。当然,98%的对象可被回收仅仅是“普通场景”下测得的数据,任何人都没有办法百分百保证每次回收都只有不多于10%的对象存活,因此Appel式回收还有一个充当罕见情况的“逃生门”的安全设计,当Survivor空间不足以容纳一次Minor GC之后存活的对象时,就需要依赖其他内存区域(实际上大多就是老年代)进行分配担保(Handle Promotion)。
标记-整理算法:
标记-复制算法在对象存活率较高时就要进行较多的复制操作,效率将会降低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
针对老年代对象的存亡特征,1974年Edward Lueders提出了另外一种有针对性的“标记-整理”(Mark-Compact)算法,其中的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存,“标记-整理”算法的示意图如下图所示。

请介绍一下分代回收机制
参考答案
当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集”(GenerationalCollection)[插图]的理论进行设计,分代收集名为理论,实质是一套符合大多数程序运行实际情况的经验法则,它建立在两个分代假说之上:
- 弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。
- 强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消亡。
这两个分代假说共同奠定了多款常用的垃圾收集器的一致的设计原则:收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄(年龄即对象熬过垃圾收集过程的次数)分配到不同的区域之中存储。把分代收集理论具体放到现在的商用Java虚拟机里,设计者一般至少会把Java堆划分为新生代(Young Generation)和老年代(Old Generation)两个区域。顾名思义,在新生代中,每次垃圾收集时都发现有大批对象死去,而每次回收后存活的少量对象,将会逐步晋升到老年代中存放。
分代收集并非只是简单划分一下内存区域那么容易,它至少存在一个明显的困难:对象不是孤立的,对象之间会存在跨代引用。假如要现在进行一次只局限于新生代区域内的收集,但新生代中的对象是完全有可能被老年代所引用的,为了找出该区域中的存活对象,不得不在固定的GC Roots之外,再额外遍历整个老年代中所有对象来确保可达性分析结果的正确性,反过来也是一样。遍历整个老年代所有对象的方案虽然理论上可行,但无疑会为内存回收带来很大的性能负担。为了解决这个问题,就需要对分代收集理论添加第三条经验法则:
- 跨代引用假说(Intergenerational Reference Hypothesis):跨代引用相对于同代引用来说仅占极少数。
依据这条假说,我们就不应再为了少量的跨代引用去扫描整个老年代,也不必浪费空间专门记录每一个对象是否存在及存在哪些跨代引用,只需在新生代上建立一个全局的数据结构(称为“记忆集”,RememberedSet),这个结构把老年代划分成若干小块,标识出老年代的哪一块内存会存在跨代引用。此后当发生Minor GC时,只有包含了跨代引用的小块内存里的对象才会被加入到GC Roots进行扫描。虽然这种方法需要在对象改变引用关系(如将自己或者某个属性赋值)时维护记录数据的正确性,会增加一些运行时的开销,但比起收集时扫描整个老年代来说仍然是划算的。
JVM中一次完整的GC流程是怎样的?
参考答案
新创建的对象一般会被分配在新生代中,常用的新生代的垃圾回收器是 ParNew 垃圾回收器,它按照 8:1:1 将新生代分成 Eden 区,以及两个 Survivor 区。某一时刻,我们创建的对象将 Eden 区全部挤满,这个对象就是挤满新生代的最后一个对象。此时,Minor GC 就触发了。
在正式 Minor GC 前,JVM 会先检查新生代中对象,是比老年代中剩余空间大还是小。为什么要做这样的检查呢?原因很简单,假如 Minor GC 之后 Survivor 区放不下剩余对象,这些对象就要进入到老年代,所以要提前检查老年代是不是够用。这样就有两种情况:
老年代剩余空间大于新生代中的对象大小,那就直接Minor GC,GC完survivor不够放,老年代也绝对够放;
老年代剩余空间小于新生代中的对象大小,这个时候就要查看是否启用了“老年代空间分配担保规则”,具体来说就是看 -XX:-HandlePromotionFailure 参数是否设置了。
老年代空间分配担保规则是这样的,如果老年代中剩余空间大小,大于历次 Minor GC 之后剩余对象的大小,那就允许进行 Minor GC。因为从概率上来说,以前的放的下,这次的也应该放的下。那就有两种情况:
老年代中剩余空间大小,大于历次Minor GC之后剩余对象的大小,进行 Minor GC;
老年代中剩余空间大小,小于历次Minor GC之后剩余对象的大小,进行Full GC,把老年代空出来再检查。
开启老年代空间分配担保规则只能说是大概率上来说,Minor GC 剩余后的对象够放到老年代,所以当然也会有万一,Minor GC 后会有这样三种情况:
- Minor GC 之后的对象足够放到 Survivor 区,皆大欢喜,GC 结束;
- Minor GC 之后的对象不够放到 Survivor 区,接着进入到老年代,老年代能放下,那也可以,GC 结束;
- Minor GC 之后的对象不够放到 Survivor 区,老年代也放不下,那就只能 Full GC。
前面都是成功 GC 的例子,还有 3 中情况,会导致 GC 失败,报 OOM:
- 紧接上一节 Full GC 之后,老年代任然放不下剩余对象,就只能 OOM;
- 未开启老年代分配担保机制,且一次 Full GC 后,老年代任然放不下剩余对象,也只能 OOM;
- 开启老年代分配担保机制,但是担保不通过,一次 Full GC 后,老年代任然放不下剩余对象,也是能 OOM。
Full GC会导致什么?
参考答案
Full GC会“Stop The World”,即在GC期间全程暂停用户的应用程序。
JVM什么时候触发GC,如何减少FullGC的次数?
参考答案
当 Eden 区的空间耗尽时 Java 虚拟机便会触发一次 Minor GC 来收集新生代的垃圾,存活下来的对象,则会被送到 Survivor 区,简单说就是当新生代的Eden区满的时候触发 Minor GC。
serial GC 中,老年代内存剩余已经小于之前年轻代晋升老年代的平均大小,则进行 Full GC。而在 CMS 等并发收集器中则是每隔一段时间检查一下老年代内存的使用量,超过一定比例时进行 Full GC 回收。
可以采用以下措施来减少Full GC的次数:
- 增加方法区的空间;
- 增加老年代的空间;
- 减少新生代的空间;
- 禁止使用System.gc()方法;
- 使用标记-整理算法,尽量保持较大的连续内存空间;
- 排查代码中无用的大对象。
如何确定对象是可回收的?
参考答案
引用计数算法:
在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。
但是,在Java领域,至少主流的Java虚拟机里面都没有选用引用计数算法来管理内存,主要原因是,这个看似简单的算法有很多例外情况要考虑,必须要配合大量额外处理才能保证正确地工作,譬如单纯的引用计数就很难解决对象之间相互循环引用的问题。
举个简单的例子:对象objA和objB都有字段instance,赋值令objA.instance=objB及objB.instance=objA,除此之外,这两个对象再无任何引用,实际上这两个对象已经不可能再被访问,但是它们因为互相引用着对方,导致它们的引用计数都不为零,引用计数算法也就无法回收它们。
可达性分析算法:
当前主流的商用程序语言的内存管理子系统,都是通过可达性分析(Reachability Analysis)算法来判定对象是否存活的。这个算法的基本思路就是通过一系列称为“GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”(Reference Chain),如果某个对象到GC Roots间没有任何引用链相连,或者用图论的话来说就是从GC Roots到这个对象不可达时,则证明此对象是不可能再被使用的。
如下图所示,对象object 5、object 6、object 7虽然互有关联,但是它们到GC Roots是不可达的,因此它们将会被判定为可回收的对象。
在Java技术体系里面,固定可作为GC Roots的对象包括以下几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。
- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
- 所有被同步锁(synchronized关键字)持有的对象。
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
对象如何晋升到老年代?
参考答案
虚拟机给每个对象定义了一个对象年龄(Age)计数器,存储在对象头中。对象通常在Eden区里诞生,如果经过第一次MinorGC后仍然存活,并且能被Survivor容纳的话,该对象会被移动到Survivor空间中,并且将其对象年龄设为1岁。对象在Survivor区中每熬过一次MinorGC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15),就会被晋升到老年代中。对象晋升老年代的年龄阈值,可以通过参数-XX:MaxTenuringThreshold设置。
为什么老年代不能使用标记复制?
参考答案
因为老年代保留的对象都是难以消亡的,而标记复制算法在对象存活率较高时就要进行较多的复制操作,效率将会降低,所以在老年代一般不能直接选用这种算法。
新生代为什么要分为Eden和Survivor,它们的比例是多少?
参考答案
现在的商用Java虚拟机大多都优先采用了“标记-复制算法”去回收新生代,该算法早期采用“半区复制”的机制进行垃圾回收。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样实现简单,运行高效,不过其缺陷也显而易见,这种复制回收算法的代价是将可用内存缩小为了原来的一半,空间浪费未免太多了一点。
实际上,新生代中的对象有98%熬不过第一轮收集,因此并不需要按照1∶1的比例来划分新生代的内存空间。在1989年,Andrew Appel提出了一种更优化的半区复制分代策略,现在称为“Appel式回收”。Appel式回收的具体做法是把新生代分为一块较大的Eden空间和两块较小的Survivor空间,每次分配内存只使用Eden和其中一块Survivor。发生垃圾搜集时,将Eden和Survivor中仍然存活的对象一次性复制到另外一块Survivor空间上,然后直接清理掉Eden和已用过的那块Survivor空间。
HotSpot虚拟机默认Eden和Survivor的大小比例是8∶1,也即每次新生代中可用内存空间为整个新生代容量的90%(Eden的80%加上一个Survivor的10%),只有一个Survivor空间,即10%的新生代是会被“浪费”的。
为什么要设置两个Survivor区域?
参考答案
设置两个 Survivor 区最大的好处就是解决内存碎片化。
我们先假设一下,Survivor 只有一个区域会怎样。Minor GC 执行后,Eden 区被清空了,存活的对象放到了 Survivor 区,而之前 Survivor 区中的对象,可能也有一些是需要被清除的。问题来了,这时候我们怎么清除它们?在这种场景下,我们只能标记清除,而我们知道标记清除最大的问题就是内存碎片,在新生代这种经常会消亡的区域,采用标记清除必然会让内存产生严重的碎片化。因为 Survivor 有 2 个区域,所以每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责兑换,这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。
这种机制最大的好处就是,整个过程中,永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的。那么,Survivor 为什么不分更多块呢?比方说分成三个、四个、五个?显然,如果 Survivor 区再细分下去,每一块的空间就会比较小,容易导致 Survivor 区满,两块 Survivor 区可能是经过权衡之后的最佳方案。
说一说你对GC算法的了解。
参考答案
标记-清除算法:
最早出现也是最基础的垃圾收集算法是“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。
它的主要缺点有两个:第一个是执行效率不稳定,如果Java堆中包含大量对象,而且其中大部分是需要被回收的,这时必须进行大量标记和清除的动作,导致标记和清除两个过程的执行效率都随对象数量增长而降低;第二个是内存空间的碎片化问题,标记、清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致当以后在程序运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。标记-清除算法的执行过程如下图所示。
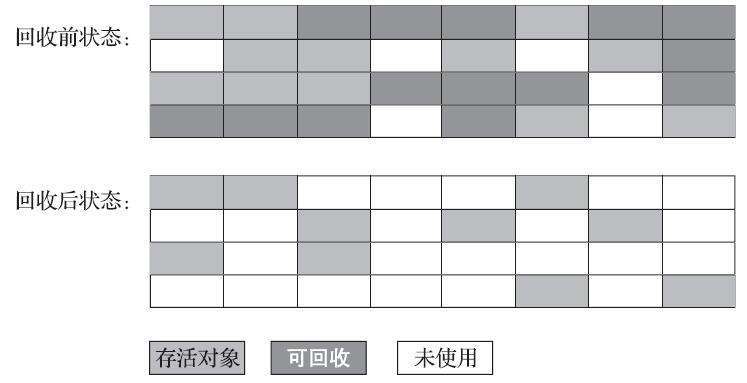
标记-复制算法:
为了解决标记-清除算法面对大量可回收对象时执行效率低的问题,1969年Fenichel提出了一种称为“半区复制”(Semispace Copying)的垃圾收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。如果内存中多数对象都是存活的,这种算法将会产生大量的内存间复制的开销,但对于多数对象都是可回收的情况,算法需要复制的就是占少数的存活对象,而且每次都是针对整个半区进行内存回收,分配内存时也就不用考虑有空间碎片的复杂情况,只要移动堆顶指针,按顺序分配即可。这样实现简单,运行高效,不过其缺陷也显而易见,这种复制回收算法的代价是将可用内存缩小为了原来的一半,空间浪费未免太多了一点。标记-复制算法的执行过程如下图所示。
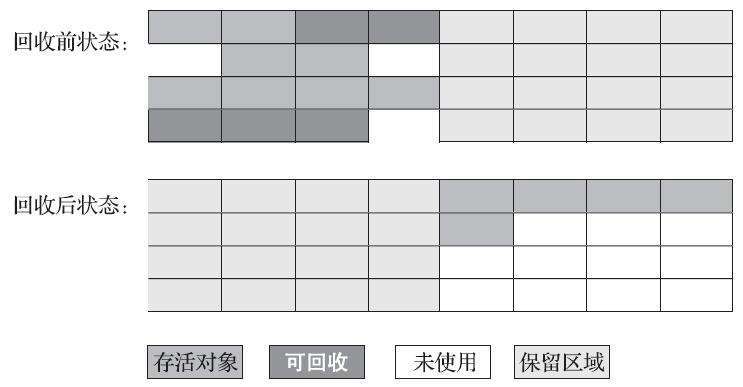
在1989年,Andrew Appel针对具备“朝生夕灭”特点的对象,提出了一种更优化的半区复制分代策略,现在称为“Appel式回收”。Appel式回收的具体做法是把新生代分为一块较大的Eden空间和两块较小的Survivor空间,每次分配内存只使用Eden和其中一块Survivor。发生垃圾搜集时,将Eden和Survivor中仍然存活的对象一次性复制到另外一块Survivor空间上,然后直接清理掉Eden和已用过的那块Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8∶1,也即每次新生代中可用内存空间为整个新生代容量的90%(Eden的80%加上一个Survivor的10%),只有一个Survivor空间,即10%的新生代是会被“浪费”的。当然,98%的对象可被回收仅仅是“普通场景”下测得的数据,任何人都没有办法百分百保证每次回收都只有不多于10%的对象存活,因此Appel式回收还有一个充当罕见情况的“逃生门”的安全设计,当Survivor空间不足以容纳一次Minor GC之后存活的对象时,就需要依赖其他内存区域(实际上大多就是老年代)进行分配担保(Handle Promotion)。
标记-整理算法:
标记-复制算法在对象存活率较高时就要进行较多的复制操作,效率将会降低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
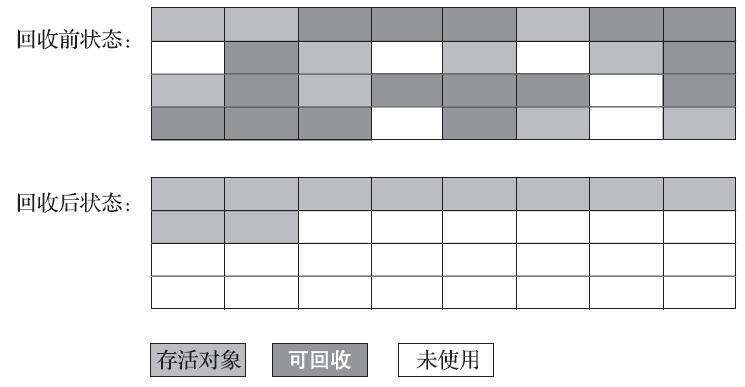
针对老年代对象的存亡特征,1974年Edward Lueders提出了另外一种有针对性的“标记-整理”(Mark-Compact)算法,其中的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存,“标记-整理”算法的示意图如下图所示。
为什么新生代和老年代要采用不同的回收算法?
参考答案
如果一个区域中大多数对象都是朝生夕灭,难以熬过垃圾收集过程的话,那么把它们集中放在一起,每次回收时只关注如何保留少量存活而不是去标记那些大量将要被回收的对象,就能以较低代价回收到大量的空间。如果剩下的都是难以消亡的对象,那把它们集中放在一块,虚拟机便可以使用较低的频率来回收这个区域,这就同时兼顾了垃圾收集的时间开销和内存的空间有效利用。
请介绍G1垃圾收集器
参考答案
G1(Garbage First)是一款主要面向服务端应用的垃圾收集器,JDK 9发布之日,G1宣告取代ParallelScavenge加Parallel Old组合,成为服务端模式下的默认垃圾收集器,而CMS则沦落至被声明为不推荐使用(Deprecate)的收集器。G1收集器是垃圾收集器技术发展历史上的里程碑式的成果,它开创了收集器面向局部收集的设计思路和基于Region的内存布局形式。
虽然G1也仍是遵循分代收集理论设计的,但其堆内存的布局与其他收集器有非常明显的差异:G1不再坚持固定大小以及固定数量的分代区域划分,而是把连续的Java堆划分为多个大小相等的独立区域(Region),每一个Region都可以根据需要,扮演新生代的Eden空间、Survivor空间,或者老年代空间。收集器能够对扮演不同角色的Region采用不同的策略去处理,这样无论是新创建的对象还是已经存活了一段时间、熬过多次收集的旧对象都能获取很好的收集效果。
Region中还有一类特殊的Humongous区域,专门用来存储大对象。G1认为只要大小超过了一个Region容量一半的对象即可判定为大对象。每个Region的大小可以通过参数 -XX:G1HeapRegionSize 设定,取值范围为1MB~32MB,且应为2的N次幂。而对于那些超过了整个Region容量的超级大对象,将会被存放在N个连续的Humongous Region 之中,G1的大多数行为都把 Humongous Region 作为老年代的一部分来进行看待,如下图所示。

虽然G1仍然保留新生代和老年代的概念,但新生代和老年代不再是固定的了,它们都是一系列区域(不需要连续)的动态集合。G1收集器之所以能建立可预测的停顿时间模型,是因为它将Region作为单次回收的最小单元,即每次收集到的内存空间都是Region大小的整数倍,这样可以有计划地避免在整个Java堆中进行全区域的垃圾收集。更具体的处理思路是让G1收集器去跟踪各个Region里面的垃圾堆积的“价值”大小,价值即回收所获得的空间大小以及回收所需时间的经验值,然后在后台维护一个优先级列表,每次根据用户设定允许的收集停顿时间(使用参数-XX:MaxGCPauseMillis指定,默认值是200毫秒),优先处理回收价值收益最大的那些Region,这也就是“Garbage First”名字的由来。这种使用Region划分内存空间,以及具有优先级的区域回收方式,保证了G1收集器在有限的时间内获取尽可能高的收集效率。
请介绍CMS垃圾收集器
参考答案
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。从名字上就可以看出CMS收集器是基于标记-清除算法实现的,它的运作过程分为四个步骤,包括:
- 初始标记(CMS initial mark);
- 并发标记(CMS concurrent mark);
- 重新标记(CMS remark);
- 并发清除(CMS concurrent sweep)。
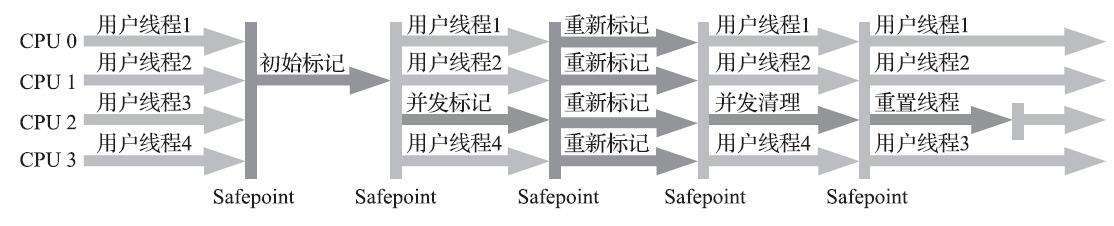
其中初始标记、重新标记这两个步骤仍然需要“Stop The World”。初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快;并发标记阶段就是从GC Roots的直接关联对象开始遍历整个对象图的过程,这个过程耗时较长但是不需要停顿用户线程,可以与垃圾收集线程一起并发运行;而重新标记阶段则是为了修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间通常会比初始标记阶段稍长一些,但也远比并发标记阶段的时间短;最后是并发清除阶段,清理删除掉标记阶段判断的已经死亡的对象,由于不需要移动存活对象,所以这个阶段也是可以与用户线程同时并发的。
由于在整个过程中耗时最长的并发标记和并发清除阶段中,垃圾收集器线程都可以与用户线程一起工作,所以从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。通过下图可以比较清楚地看到CMS收集器的运作步骤中并发和需要停顿的阶段。
CMS收集器还远达不到完美的程度,它至少有以下三个明显的缺点:
首先,CMS收集器对处理器资源非常敏感。在并发阶段,它虽然不会导致用户线程停顿,但却会因为占用了一部分线程(或者说处理器的计算能力)而导致应用程序变慢,降低总吞吐量。
然后,由于CMS收集器无法处理“浮动垃圾”(Floating Garbage),有可能出现“Con-current Mode Failure”失败进而导致另一次完全“Stop TheWorld”的Full GC的产生。
还有最后一个缺点,CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往会出现老年代还有很多剩余空间,但就是无法找到足够大的连续空间来分配当前对象,而不得不提前触发一次Full GC的情况。
内存泄漏和内存溢出有什么区别?
参考答案
内存泄漏(memory leak):内存泄漏指程序运行过程中分配内存给临时变量,用完之后却没有被GC回收,始终占用着内存,既不能被使用也不能分配给其他程序,于是就发生了内存泄漏。
内存溢出(out of memory):简单地说内存溢出就是指程序运行过程中申请的内存大于系统能够提供的内存,导致无法申请到足够的内存,于是就发生了内存溢出。
什么是内存泄漏,怎么解决?
参考答案
内存泄漏的根本原因是长生命周期的对象持有短生命周期对象的引用,尽管短生命周期的对象已经不再需要,但由于长生命周期对象持有它的引用而导致不能被回收。以发生的方式来分类,内存泄漏可以分为4类:
- 常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
- 偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
- 一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。
- 隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
避免内存泄漏的几点建议:
- 尽早释放无用对象的引用。
- 避免在循环中创建对象。
- 使用字符串处理时避免使用String,应使用StringBuffer。
- 尽量少使用静态变量,因为静态变量存放在永久代,基本不参与垃圾回收。
什么是内存溢出,怎么解决?
参考答案
内存溢出(out of memory):简单地说内存溢出就是指程序运行过程中申请的内存大于系统能够提供的内存,导致无法申请到足够的内存,于是就发生了内存溢出。
引起内存溢出的原因有很多种,常见的有以下几种:
- 内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
- 集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
- 代码中存在死循环或循环产生过多重复的对象实体;
- 使用的第三方软件中的BUG;
- 启动参数内存值设定的过小。
内存溢出的解决方案:
- 第一步,修改JVM启动参数,直接增加内存。
- 第二步,检查错误日志,查看“OutOfMemory”错误前是否有其它异常或错误。
- 第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。
- 第四步,使用内存查看工具动态查看内存使用情况。
哪些区域会OOM,怎么触发OOM?
参考答案
除了程序计数器外,虚拟机内存的其他几个运行时区域都有发生OOM异常的可能。
Java堆溢出
Java堆用于储存对象实例,我们只要不断地创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么随着对象数量的增加,总容量触及最大堆的容量限制后就会产生内存溢出异常。
虚拟机栈和本地方法栈溢出
HotSpot虚拟机中并不区分虚拟机栈和本地方法栈,如果虚拟机的栈内存允许动态扩展,当扩展栈容量无法申请到足够的内存时,将抛出OutOfMemoryError异常。
方法区和运行时常量池溢出
方法区溢出也是一种常见的内存溢出异常,在经常运行时生成大量动态类的应用场景里,就应该特别关注这些类的回收状况。这类场景常见的包括:程序使用了CGLib字节码增强和动态语言、大量JSP或动态产生JSP文件的应用(JSP第一次运行时需要编译为Java类)、基于OSGi的应用(即使是同一个类文件,被不同的加载器加载也会视为不同的类)等。
在JDK 6或更早之前的HotSpot虚拟机中,常量池都是分配在永久代中,即常量池是方法去的一部分,所以上述问题在常量池中也同样会出现。而HotSpot从JDK 7开始逐步“去永久代”的计划,并在JDK 8中完全使用元空间来代替永久代,所以上述问题在JDK 8中会得到避免。
本地直接内存溢出
直接内存(Direct Memory)的容量大小可通过-XX:MaxDirectMemorySize参数来指定,如果不去指定,则默认与Java堆最大值(由-Xmx指定)一致。如果直接通过反射获取Unsafe实例进行内存分配,并超出了上述的限制时,将会引发OOM异常
补充:Minor GC 和Major GC、Full GC
由于对象进行了分代处理,因此垃圾回收区域、时间也不一样。GC有两种类型:Scavenge GC和Full GC。对于一个拥有终结方法的对象,在垃圾收集器释放对象前必须执行终结方法。但是当垃圾收集器第二次收集这个对象时便不会再次调用终结方法。
Minor Gc
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Minor GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区,然后整理Survivor的两个区。这种方式的GC是对新生代的Eden区进行,不会影响到老年代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。
Full Gc/Major GC
发生在老年代,一般情况下,触发老年代 GC的时候不会触发 Minor GC,但是通过配置,可以在 Full GC 之前进行一次 Minor GC 这样可以加快老年代的回收速度。
对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个对进行回收,所以比Minor GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。有如下原因可能导致Full GC:
- 老年代(Tenured)被写满
- 持久代(Perm)被写满
- System.gc()被显示调用
补充:堆里面的分区:Eden,survival (from+ to),老年代
答:堆里面分为新生代和老生代(java8 取消了永久代,采用了 Metaspace),新生代包含 Eden+Survivor 区,survivor 区里面分为 from 和 to 区,内存回收时,如果用的是复制算法,从 from 复制到 to,当经过一次或者多次 GC 之后,存活下来的对象会被移动到老年区,当 JVM 内存不够用的时候,会触发 Full GC,清理 JVM 老年区当新生区满了之后会触发 YGC,先把存活的对象放到其中一个 Survice区,然后进行垃圾清理。因为如果仅仅清理需要删除的对象,这样会导致内存碎片,因此一般会把 Eden 进行完全的清理,然后整理内存。那么下次 GC 的时候,就会使用下一个 Survive,这样循环使用。如果有特别大的对象,新生代放不下,就会使用老年代的担保,直接放到老年代里面。因为 JVM 认为,一般大对象的存活时间一般比较久远。
1.Eden区
Eden区位于java堆的年轻代,是新对象分配内存的地方,由于堆是所有线程共享的,因此在堆上分配内存需要加锁。而Sun JDK为提升效率,会为每个新建的线程在Eden上分配一块独立的空间由该线程独享,这块空间称为TLAB(Thread Local Allocation Buffer)。在TLAB上分配内存不需要加锁,因此JVM在给线程中的对象分配内存时会尽量在TLAB上分配。如果对象过大或TLAB用完,则仍然在堆上进行分配。如果Eden区内存也用完了,则会进行一次Minor GC(young GC)。
2.Survival from to
Survival区与Eden区相同都在java堆的年轻代。Survival区有两块,一块称为from区,另一块为to区,这两个区是相对的,在发生一次Minor GC后,from区就会和to区互换。在发生Minor GC时,Eden区和Survivalfrom区会把一些仍然存活的对象复制进Survival to区,并清除内存。Survival to区会把一些存活得足够旧的对象移老年代。
3.老年代
老年代里存放的都是存活时间较久的,大小较大的对象,因此年老代使用标记整理算法。当年老代容量满的时候,会触发一次Major GC(full GC),回收年老代和年轻代中不再被使用的对象资源。
补充:SafePoint 是什么?
答:比如 GC 的时候必须要等到 java 线程都进入到 safepoint 的时候 VMThread 才能开始 执行 GC。
- 循环的末尾(防止大循环的时候一直不进入 safepoint,而其他线程在等待它进入safepoint)。
- 方法返回前。
- 调用方法的call之后4。
- 抛出异常的位置。
详见:https://blog.csdn.net/szw906689771/article/details/113941741
补充:GC 收集器
- Serial收集器
Serial收集器是最基本的收集器,这是一个单线程收集器,它“单线程”的意义不仅仅是说明它只用一个线程去完成垃圾收集工作,更重要的是在它进行垃圾收集工作时,必须暂停其他工作线程,直到它收集完成。Sun将这件事称之为”Stop the world“。
没有一个收集器能完全不停顿,只是停顿的时间长短。
虽然Serial收集器的缺点很明显,但是它仍然是JVM在Client模式下的默认新生代收集器。它有着优于其他收集器的地方:简单而高效(与其他收集器的单线程比较),Serial收集器由于没有线程交互的开销,专心只做垃圾收集自然也获得最高的效率。在用户桌面场景下,分配给JVM的内存不会太多,停顿时间完全可以在几十到一百多毫秒之间,只要收集不频繁,这是完全可以接受的。
- ParNew收集器
ParNew是Serial的多线程版本,在回收算法、对象分配原则上都是一致的。ParNew收集器是许多运行在Server模式下的默认新生代垃圾收集器,其主要在于除了Serial收集器,目前只有ParNew收集器能够与CMS收集器配合工作。
- Parallel Scavenge收集器
Parallel Scavenge收集器是一个新生代垃圾收集器,其使用的算法是复制算法,也是并行的多线程收集器。
Parallel Scavenge 收集器更关注可控制的吞吐量,吞吐量等于运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)。直观上,只要最大的垃圾收集停顿时间越小,吞吐量是越高的,但是GC停顿时间的缩短是以牺牲吞吐量和新生代空间作为代价的。比如原来10秒收集一次,每次停顿100毫秒,现在变成5秒收集一次,每次停顿70毫秒。停顿时间下降的同时,吞吐量也下降了。
停顿时间越短就越适合需要与用户交互的程序;而高吞吐量则可以最高效的利用CPU的时间,尽快的完成计算任务,主要适用于后台运算。
- Serial Old收集器
Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器,采用“标记-整理算法”进行回收。其运行过程与Serial收集器一样。
- Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法进行垃圾回收。其通常与Parallel Scavenge收集器配合使用,“吞吐量优先”收集器是这个组合的特点,在注重吞吐量和CPU资源敏感的场合,都可以使用这个组合。
- CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短停顿时间为目标的收集器,CMS收集器采用标记–清除算法,运行在老年代。主要包含以下几个步骤:
- 初始标记
- 并发标记
- 重新标记
- 并发清除
其中初始标记和重新标记仍然需要“Stop the world”。初始标记仅仅标记GC Root能直接关联的对象,并发标记就是进行GC Root Tracing过程,而重新标记则是为了修正并发标记期间,因用户程序继续运行而导致标记变动的那部分对象的标记记录。
由于整个过程中最耗时的并发标记和并发清除,收集线程和用户线程一起工作,所以总体上来说,CMS收集器回收过程是与用户线程并发执行的。虽然CMS优点是并发收集、低停顿,很大程度上已经是一个不错的垃圾收集器,但是还是有三个显著的缺点:
- CMS收集器对CPU资源很敏感。在并发阶段,虽然它不会导致用户线程停顿,但是会因为占用一部分线程(CPU资源)而导致应用程序变慢。
- CMS收集器不能处理浮动垃圾。所谓的“浮动垃圾”,就是在并发标记阶段,由于用户程序在运行,那么自然就会有新的垃圾产生,这部分垃圾被标记过后,CMS无法在当次集中处理它们,只好在下一次GC的时候处理,这部分未处理的垃圾就称为“浮动垃圾”。也是由于在垃圾收集阶段程序还需要运行,即还需要预留足够的内存空间供用户使用,因此CMS收集器不能像其他收集器那样等到老年代几乎填满才进行收集,需要预留一部分空间提供并发收集时程序运作使用。要是CMS预留的内存空间不能满足程序的要求,这是JVM就会启动预备方案:临时启动Serial Old收集器来收集老年代,这样停顿的时间就会很长。
- 由于CMS使用标记–清除算法,所以在收集之后会产生大量内存碎片。当内存碎片过多时,将会给分配大对象带来困难,这是就会进行Full GC。
- G1收集器
G1收集器与CMS相比有很大的改进:
- G1收集器采用标记–整理算法实现。
- 可以非常精确地控制停顿。
G1收集器可以实现在基本不牺牲吞吐量的情况下完成低停顿的内存回收,这是由于它极力的避免全区域的回收,G1收集器将java堆(包括新生代和老年代)划分为多个区域(Region),并在后台维护一个优先列表,每次根据允许的时间,优先回收垃圾最多的区域 。
补充:描述一下 JVM 加载 class 文件的原理机制?
JVM 中类的装载是由类加载器(ClassLoader)和它的子类来实现的,java中的类加载器是一个重要的 java 运行时系统组件,它负责在运行时查找和装入类文件中的类。
由于 java 的跨平台性,经过编译的 java 源程序并不是一个可执行程序,而是 一个或多个类文件。当 java 程序需要使用某个类时,JVM 会确保这个类已经被 加载、连接(验证、准备和解析)和初始化。类的加载是指把类的.class 文件 中的数据读入到内存中,通常是创建一个字节数组读入.class 文件,然后产生 与所加载类对应的 Class 对象。加载完成后,Class 对象还不完整,所以此时 的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引 用)三个步骤。最后 JVM 对类进行初始化,包括:1)如果类存在直接的父类并 且这个类还没有被初始化,那么就先初始化父类;2)如果类中存在初始化语 句,就依次执行这些初始化语句。
类的加载是由类加载器完成的,类加载器包括:根加载器(BootStrap)、扩展 加载器(Extension)、系统加载器(System)和用户自定义类加载器 (java.lang.ClassLoader 的子类)。从 java 2(JDK 1.2)开始,类加载过程 采取了父亲委托机制(PDM)。PDM 更好的保证了 java 平台的安全性,在该机 制中,JVM 自带的 Bootstrap 是根加载器,其他的加载器都有且仅有一个父类 加载器。类的加载首先请求父类加载器加载,父类加载器无能为力时才由其子 类加载器自行加载。JVM 不会向 java 程序提供对 Bootstrap 的引用。
补充:对象的内存布局
对象在内存中的存储的布局可以分为3块区域:
- 对象头(Header):对象头包含两个部分的信息,第一部分是对象自身的运行时数据,如哈希码、GC分代年龄、持有的锁等等;第二部分是类型指针,指向它的类元数据的指针,通过这个虚拟机来确定这个对象是哪个类的实例。
- 实例数据(Instance Data):对象真正存储的数据,就是程序代码中定义的字段内容。
- 对齐填充(Padding):用于使对象的开头必须是8字节的整数倍,无特殊意义。
补充:对象的访问定位
对于这句代码:
Object objectRef = new Object(); |
Object objectRef 这部分将会反映到java栈的本地变量中,作为一个reference类型数据出现。而“new Object()”这部分将会反映到java堆中,形成一块存储Object类型所有实例数据值的结构化内存,根据具体类型以及虚拟机实现的对象内存布局的不同,这块内存的长度是不固定。另外,在java堆中还必须包括能查找到此对象类型数据(如对象类型、父类、实现的接口、方法等)的地址信息,这些数据类型存储在方法区中。
有两种基本的定位方式:
句柄访问(间接):在java堆中划分一块内存作为句柄池(即一个句柄列表),reference中存储的就是对象在句柄池中的地址,得到了句柄池的地址就可以知道对象的实例数据和类型数据的位置。

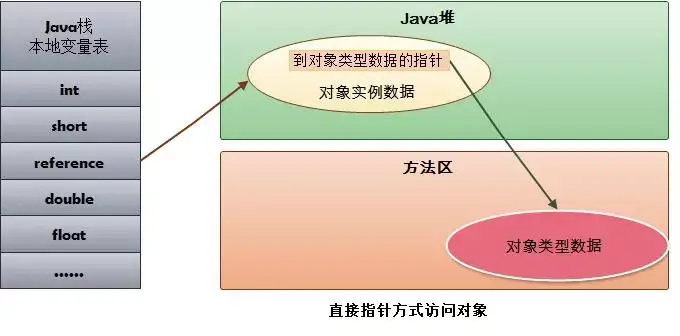
直接指针访问(直接):reference中存储的直接就是对象的实例数据的地址,而实例数据中自己有一个指针存储对象类型数据的地址(方法区中),不需要reference来存储。
来源:https://www.nowcoder.com/tutorial/94/ea1986fcff294f6292385703e94689e8