Dubbo、Zookeeper
Zookeeper
Zookeeper笔记:https://blog.csdn.net/hancoder/article/details/107054128
下载安装
apache-zookeeper-3.5.6-bin.tar.gz
1、环境准备
ZooKeeper服务器是用Java创建的,它运行在JVM之上。需要安装JDK 7或更高版本。
2、上传
将下载的ZooKeeper放到/opt/ZooKeeper目录下
上传zookeeper alt+p |
3、解压
将tar包解压到/opt/zookeeper目录下
tar -zxvf apache-ZooKeeper-3.5.6-bin.tar.gz |
配置启动
1、配置zoo.cfg
进入到conf目录拷贝一个zoo_sample.cfg并完成配置
进入到conf目录 |
修改zoo.cfg
打开目录 |
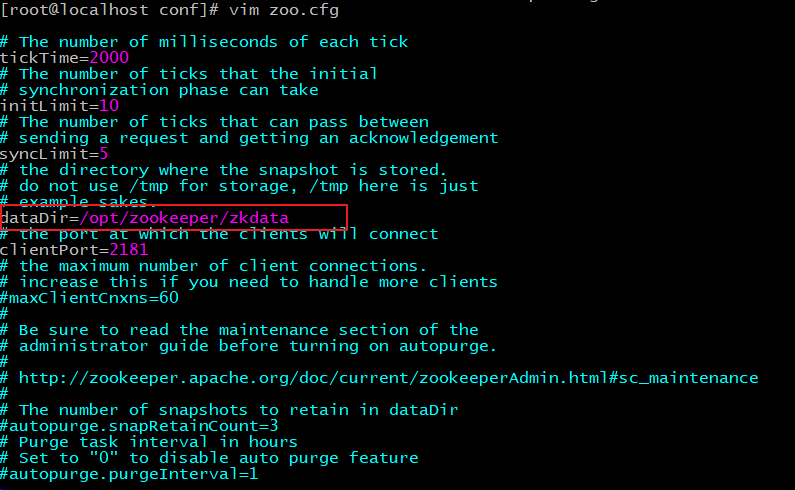
修改存储目录:dataDir=/opt/zookeeper/zkdata
2、启动ZooKeeper
cd /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/bin/ |

看到上图表示ZooKeeper成功启动
3、查看ZooKeeper状态
./zkServer.sh status |
zookeeper启动成功。standalone代表zk没有搭建集群,现在是单节点

zookeeper没有启动

节点
ZooKeeper 是一个树形目录服务,其数据模型和Unix的文件系统目录树很类似,拥有一个层次化结构。
这里面的每一个节点都被称为: ZNode,每个节点上都会保存自己的数据和节点信息。
节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点之下。
节点可以分为四大类:
- PERSISTENT 持久化节点
- EPHEMERAL 临时节点 :-e
- PERSISTENT_SEQUENTIAL 持久化顺序节点 :-s
- EPHEMERAL_SEQUENTIAL 临时顺序节点 :-es
命令操作
服务端
- 启动 ZooKeeper 服务: ./zkServer.sh start
- 查看 ZooKeeper 服务状态: ./zkServer.sh status
- 停止 ZooKeeper 服务: ./zkServer.sh stop
- 重启 ZooKeeper 服务: ./zkServer.sh restart
客户端
- 连接ZooKeeper服务端 ./zkCli.sh –server ip:port
- 断开连接quit
- 查看命令帮助help
- 显示指定目录下节点ls 目录
- 创建节点create /节点path value
- 获取节点值get /节点path
- 设置节点值set /节点path value
- 删除单个节点delete /节点path
- 删除带有子节点的节点deleteall /节点path
- 创建临时节点create -e /节点path value
- 创建顺序节点create -s /节点path value
- 查询节点详细信息ls –s /节点path
- czxid:节点被创建的事务ID
- ctime: 创建时间
- mzxid: 最后一次被更新的事务ID
- mtime: 修改时间
- pzxid:子节点列表最后一次被更新的事务ID
- cversion:子节点的版本号
- dataversion:数据版本号
- aclversion:权限版本号
- ephemeralOwner:用于临时节点,代表临时节点的事务ID,如果为持久节点则为0
- dataLength:节点存储的数据的长度
- numChildren:当前节点的子节点个数
Curator
常见的ZooKeeper Java API :
- 原生Java API
- ZkClient
- Curator
Curator API 常用操作
建立连接(具体见代码)
添加节点
删除节点
修改节点
查询节点
Watch事件监听
ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
ZooKeeper 中引入了Watcher机制来实现了发布/订阅功能能,能够让多个订阅者同时监听某一个对象,当一个对象自身状态变化时,会通知所有订阅者。
ZooKeeper 原生支持通过注册Watcher来进行事件监听,但是其使用并不是特别方便
需要开发人员自己反复注册Watcher,比较繁琐。
Curator引入了 Cache 来实现对 ZooKeeper 服务端事件的监听。
ZooKeeper提供了三种Watcher:
- NodeCache : 只是监听某一个特定的节点
- PathChildrenCache : 监控一个ZNode的子节点.
- TreeCache : 可以监控整个树上的所有节点,类似于PathChildrenCache和NodeCache的组合
分布式锁实现
在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM之下,没有任何问题。
但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。
那么就需要一种更加高级的锁机制,来处理种跨机器的进程之间的数据同步问题——这就是分布式锁。
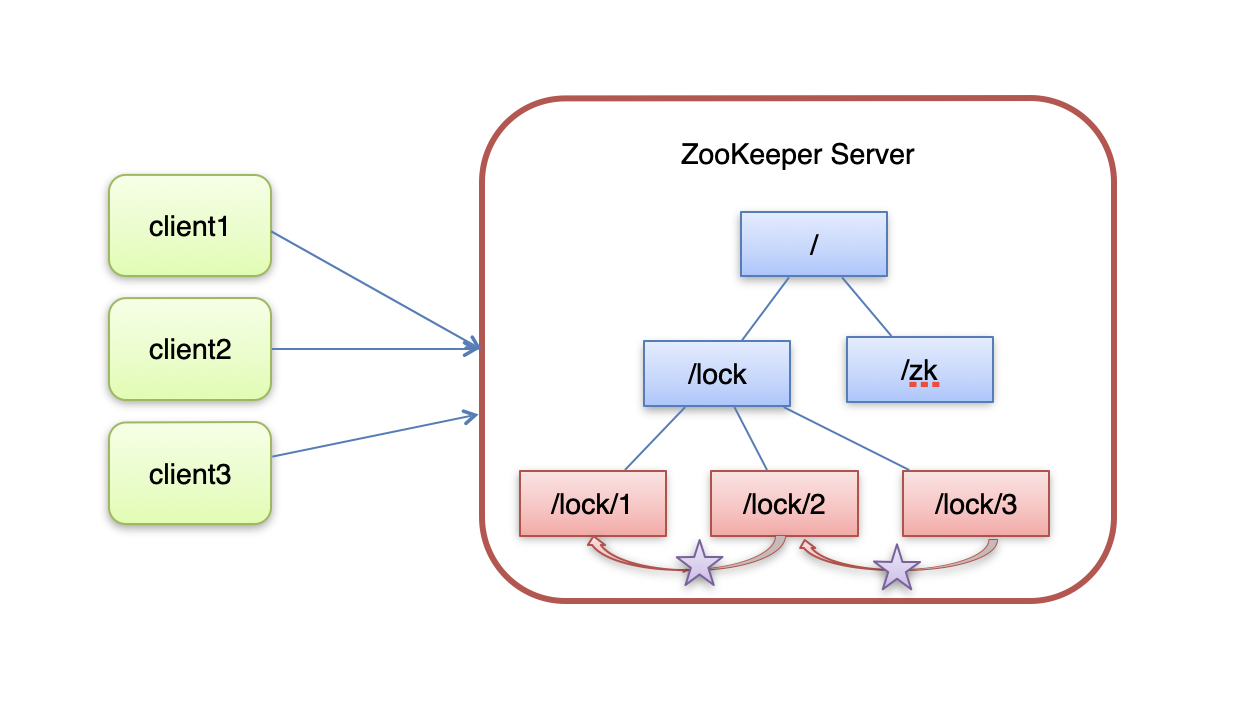
ZooKeeper分布式锁原理
- 核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
客户端获取锁时,在lock节点下创建临时顺序节点。
然后获取lock下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
如果发现比自己小的那个节点被删除,则客户端的
Watcher会收到相应通知,此时再次判断自己创建的节点
是否是lock子节点中序号最小的,如果是则获取到了锁,
如果不是则重复以上步骤继续获取到比自己小的一个节点
并注册监听。
Curator实现分布式锁API
在Curator中有五种锁方案:
- InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
- InterProcessMutex:分布式可重入排它锁
- InterProcessReadWriteLock:分布式读写锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器
- InterProcessSemaphoreV2:共享信号量
Zookeeper集群
介绍
Leader选举:
Serverid:服务器ID
比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大。
Zxid:数据ID
服务器中存放的最大数据ID.值越大说明数据 越新,在选举算法中数据越新权重越大。
在Leader选举的过程中,如果某台ZooKeeper
获得了超过半数的选票,则此ZooKeeper就可以成为Leader了。
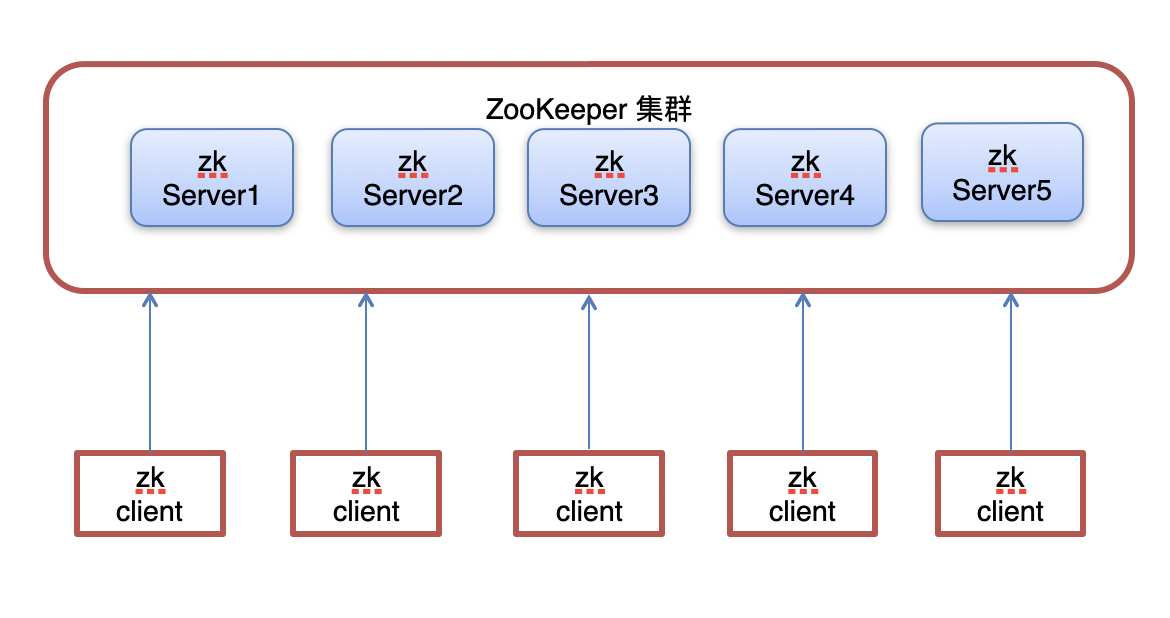
集群角色
在ZooKeeper集群服中务中有三个角色:
Leader 领导者 :
处理事务请求
集群内部各服务器的调度者
Follower 跟随者 :
处理客户端非事务请求,转发事务请求给Leader服务器
参与Leader选举投票
Observer 观察者:
- 处理客户端非事务请求,转发事务请求给Leader服务器
搭建Zookeeper集群
1.1 搭建要求
真实的集群是需要部署在不同的服务器上的,但是在我们测试时同时启动很多个虚拟机内存会吃不消,所以我们通常会搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分。
我们这里要求搭建一个三个节点的Zookeeper集群(伪集群)。
1.2 准备工作
重新部署一台虚拟机作为我们搭建集群的测试服务器。
(1)安装JDK 【此步骤省略】。
(2)Zookeeper压缩包上传到服务器
(3)将Zookeeper解压 ,建立/usr/local/zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
/usr/local/zookeeper-cluster/zookeeper-1
/usr/local/zookeeper-cluster/zookeeper-2
/usr/local/zookeeper-cluster/zookeeper-3
[root@localhost ~]# mkdir /usr/local/zookeeper-cluster |
(4)创建data目录 ,并且将 conf下zoo_sample.cfg 文件改名为 zoo.cfg
mkdir /usr/local/zookeeper-cluster/zookeeper-1/data |
(5) 配置每一个Zookeeper 的dataDir 和 clientPort 分别为2181 2182 2183
修改/usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg |
修改/usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg |
修改/usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg |
1.3 配置集群
(1)在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器的ID
echo 1 >/usr/local/zookeeper-cluster/zookeeper-1/data/myid |
(2)在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
集群服务器IP列表如下
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg |
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
1.4 启动集群
启动集群就是分别启动每个实例。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start |
启动后我们查询一下每个实例的运行状态
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status |
先查询第一个服务

Mode为follower表示是跟随者(从)
再查询第二个服务Mod 为leader表示是领导者(主)

查询第三个为跟随者(从)

1.5 模拟集群异常
(1)首先我们先测试如果是从服务器挂掉,会怎么样
把3号服务器停掉,观察1号和2号,发现状态并没有变化
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh stop |
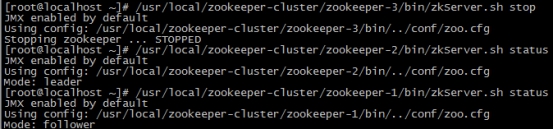
由此得出结论,3个节点的集群,从服务器挂掉,集群正常
(2)我们再把1号服务器(从服务器)也停掉,查看2号(主服务器)的状态,发现已经停止运行了。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh stop |

由此得出结论,3个节点的集群,2个从服务器都挂掉,主服务器也无法运行。因为可运行的机器没有超过集群总数量的半数。
(3)我们再次把1号服务器启动起来,发现2号服务器又开始正常工作了。而且依然是领导者。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start |

(4)我们把3号服务器也启动起来,把2号服务器停掉,停掉后观察1号和3号的状态。
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start |
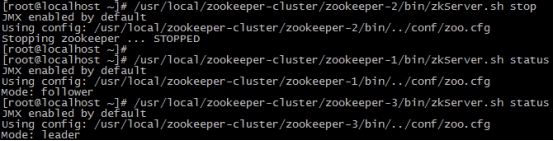
发现新的leader产生了~
由此我们得出结论,当集群中的主服务器挂了,集群中的其他服务器会自动进行选举状态,然后产生新得leader
(5)我们再次测试,当我们把2号服务器重新启动起来启动后,会发生什么?2号服务器会再次成为新的领导吗?我们看结果
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start |


我们会发现,2号服务器启动后依然是跟随者(从服务器),3号服务器依然是领导者(主服务器),没有撼动3号服务器的领导地位。
由此我们得出结论,当领导者产生后,再次有新服务器加入集群,不会影响到现任领导者。
dubbo-admin
安装
1、环境准备
dubbo-admin 是一个前后端分离的项目。前端使用vue,后端使用springboot,安装 dubbo-admin 其实就是部署该项目。我们将dubbo-admin安装到开发环境上。要保证开发环境有jdk,maven,nodejs
安装node**(如果当前机器已经安装请忽略)**
因为前端工程是用vue开发的,所以需要安装node.js,node.js中自带了npm,后面我们会通过npm启动
下载地址
https://nodejs.org/en/ |

2、下载 Dubbo-Admin
进入github,搜索dubbo-admin
https://github.com/apache/dubbo-admin |
下载:
3、把下载的zip包解压到指定文件夹(解压到那个文件夹随意)

4、修改配置文件
解压后我们进入…\dubbo-admin-develop\dubbo-admin-server\src\main\resources目录,找到 application.properties 配置文件 进行配置修改

修改zookeeper地址

centers in dubbo2.7 |
admin.registry.address注册中心
admin.config-center 配置中心
admin.metadata-report.address元数据中心
5、打包项目
在 dubbo-admin-develop 目录执行打包命令
mvn clean package |
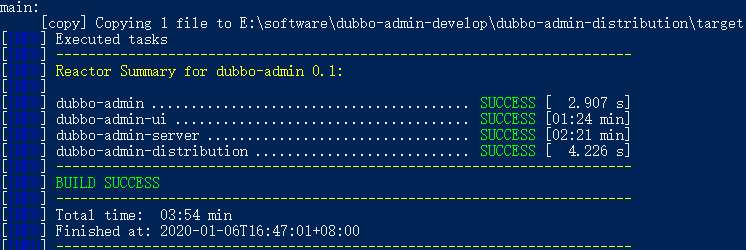
6、启动后端
切换到目录
dubbo-Admin-develop\dubbo-admin-distribution\target> |
执行下面的命令启动 dubbo-admin,dubbo-admin后台由SpringBoot构建。
java -jar .\dubbo-admin-0.1.jar |

7、前台后端
dubbo-admin-ui 目录下执行命令
npm run dev |

8、访问
浏览器输入。用户名密码都是root
http://localhost:8081/ |
简单使用

注意:Dubbo Admin【服务Mock】【服务统计】将在后续版本发布….
在上面的步骤中,我们已经进入了Dubbo-Admin的主界面,在【快速入门】章节中,我们定义了服务生产者、和服务消费者,下面我们从Dubbo-Admin管理界面找到这个两个服务
1、点击服务查询

2、查询结果
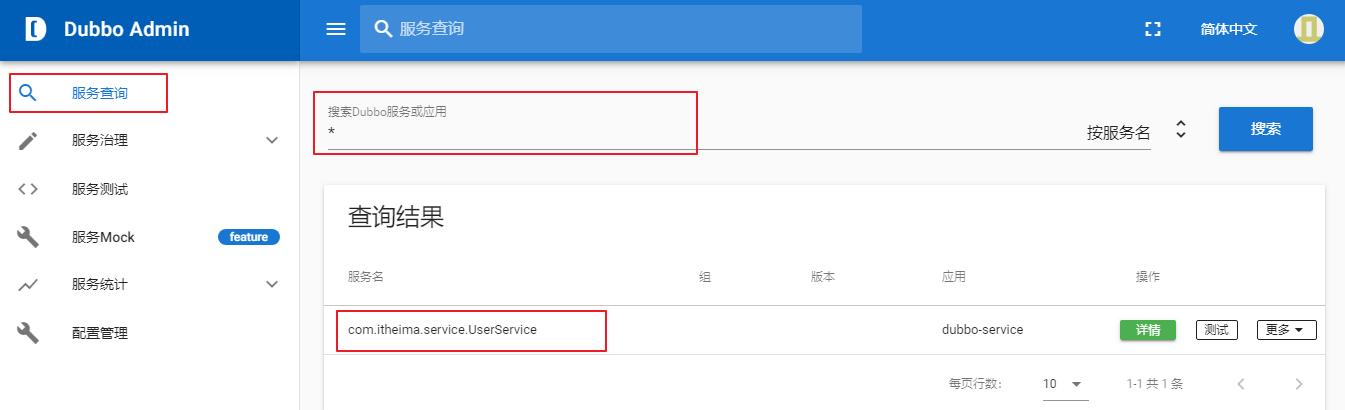
A:输入的查询条件com.itheima.service.UserService
B:搜索类型,主要分为【按服务名】【按IP地址】【按应用】三种类型查询
C:搜索结果
3.1.4 dubo-admin查看详情
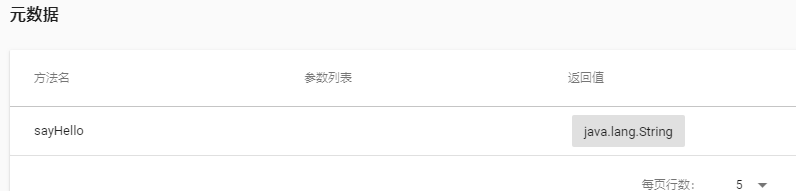
我们查看com.itheima.service.UserService (服务提供者)的具体详细信息,包含【元数据信息】
1)点击详情

从【详情】界面查看,主要分为3个区域
A区域:主要包含服务端 基础信息比如服务名称、应用名称等
B区域:主要包含了生产者、消费者一些基本信息
C区域:是元数据信息,注意看上面的图,元数据信息是空的
我们需要打开我们的生产者配置文件加入下面配置
<!-- 元数据配置 --> |
重新启动生产者,再次打开Dubbo-Admin
这样我们的元数据信息就出来了