枚举
枚举类是用final修饰的,枚举类不能被继承!
枚举类默认继承了java.lang.Enum枚举类。
枚举类的第一行都是常量,存储都是枚举类的对象。
枚举类的第一行必须是罗列枚举类的实例名称。
java建议做信息标志和信息分类应该使用枚举实现:最优雅的方式。
修饰符 enum 枚举名称{ 第一行都是罗列枚举实例的名称。 } enum Season { SPRING , SUMMER , AUTUMN , WINTER; } public final class Season extends java .lang.Enum<Season> { public static final Season SPRING = new Season (); public static final Season SUMMER = new Season (); public static final Season AUTUMN = new Season (); public static final Season WINTER = new Season (); public static Season[] values(); public static Season valueOf (java.lang.String) ; }
API
Season[] ss = Season.values(); Season s2 = Season.AUTUMN;System.out.println(s2.ordinal()); enum Season { SPRING, SUMMER , AUTUMN, WINTER ; }
enum Oritation { UP , DOWN , LEFT , RIGHT ; } public static void move (Oritation o) { switch (o){ case UP: System.out.println("让🐎往👆蹦~~~~" ); break ; case DOWN: System.out.println("让🐎往👇蹦~~~~" ); break ; case LEFT: System.out.println("让🐎往👈蹦~~~~" ); break ; case RIGHT: System.out.println("让🐎往👉蹦~~~~" ); break ; } }
递归 直接递归:自己的方法调用自己。
间接递归:自己的方法调用别的方法,别的方法又调用自己。
已知:f(x) = f(x - 1 ) + 1 (恒等式) 已知:f(1 ) = 1 求: f(10 ) = ? 计算流程: f(10 ) = f(9 ) + 1 f(9 ) = f(8 ) + 1 f(8 ) = f(7 ) + 1 f(7 ) = f(6 ) + 1 f(6 ) = f(5 ) + 1 f(5 ) = f(4 ) + 1 f(4 ) = f(3 ) + 1 f(3 ) = f(2 ) + 1 f(2 ) = f(1 ) + 1 f(1 ) = 1 递归的三要素(理论): 1. 递归的终结点: f(1 ) = 1 2. 递归的公式:f(x) = f(x - 1 ) + 1 3. 递归的方向:必须走向终结点
public static int f (int x) { if (x == 1 ) { return 1 ; }else { return f(x - 1 ) + 1 ; } }
拓展:递归的核心思想-公式转换 已知: f = f + 2 f = 1 求: f = ? 公式转换: f = f+2 f = f+2 f = f- 2 ; 递归算法的三要素: (1 )递归的公式: f = f- 2 ; (2 )递归的终结点: f = 1 (3 )递归的方向:必须走向终结点。
public static int f (int n) { if (n == 1 ) { return 1 ; }else { return f(n-1 )- 2 ; } }
递归的经典案例。
猴子第一天摘了若干个桃子,当即吃了一半,觉得好不过瘾,然后又多吃了一个。 第二天又吃了前一天剩下的一半,觉得好不过瘾,然后又多吃了一个。 以后每天都是如此 等到第十天再吃的时候发现只有1 个桃子,请问猴子第一天总共摘了多少个桃子。 公式: f (x+1 ) f (x) - f (x) / 2 - 1 2 f (x+1 ) = 2 f (x) - f (x) - 2 2 f (x+1 ) = f (x) - 2 f (x) 2 f (x+1 )+2 递归的三要素: (1 )公式:f (x) = 2 f (x+1 )+2 (2 )终结点:f (10 ) = 1 (3 )递归的方向:走向了终结点
public static int f (int x) { if ( x == 10 ){ return 1 ; }else { return 2 *f(x+1 )+2 ; } }
f (n ) = 1 + 2 + 3 + 4 + 5 + 6 + ...n -1 + n ;f (n ) = f (n -1) + n 流程: f (5) = return f (4) + 5 = 1 + 2 + 3 + 4 + 5f (4) = return f (3) + 4 = 1 + 2 + 3 + 4f (3) = return f (2) + 3 = 1 + 2 + 3f (2) = return f (1) + 2 = 1 + 2f (1) = return 1递归的核心三要素: (1)递归的终点接: f (1) = 1 (2)递归的公式: f (n ) = f (n -1) + n (3)递归的方向必须走向终结点:
public static int f (int n) { if (n == 1 ) return 1 ; return f(n-1 ) + n; }
n!= 1*2 *3 *4 *5 *6 *.. .*(n-1)*n。 f(n) = 1*2 *3 *4 *5 *6 *.. .*(n-1)*n f(n) = f(n-1)*n 流程: f(5) = f(4) * 5 ; = 1*2 *3 *4 *5 f(4) = f(3) * 4 ; = 1*2 *3 *4 f(3) = f(2) * 3 ; = 1*2 *3 f(2) = f(1) * 2 ; = 1*2 f(1) = 1 递归的核心三要素: (1)递归的终点接: f(1) = 1 (2)递归的公式 f(n) = f(n-1)*n (3)递归的方向必须走向终结点
public static int f (int n) { if (n == 1 ){ return 1 ; }else { return f(n-1 )*n; } }
需求:希望去D:/soft 目录寻找出eclipse.exe文件。 分析: (1)定义一个方法用于做搜索。 (2)进入方法中进行业务搜索分析。 小结: 非规律化递归应该按照业务流程开发!
public static void searchFiles (File dir , String fileName) { if (dir.exists() && dir.isDirectory()){ File[] files = dir.listFiles(); if (files!=null && files.length > 0 ){ for (File f : files) { if (f.isFile()){ if (f.getName().contains(fileName)){ System.out.println(f.getAbsolutePath()); try { Runtime r = Runtime.getRuntime(); r.exec(f.getAbsolutePath()); } catch (IOException e) { e.printStackTrace(); } } }else { searchFiles(f ,fileName); } } } } }
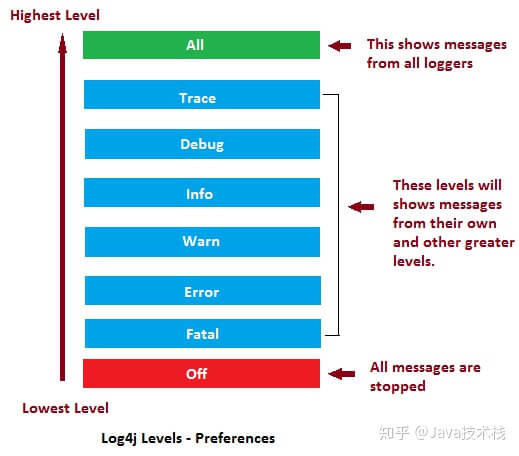
日志级别
日志级别
描述
OFF
关闭:最高级别,不打印日志。
FATAL
致命:指明非常严重的可能会导致应用终止执行错误事件。
灾难信息,合并计入ERROR
ERROR
错误:指明错误事件,但应用可能还能继续运行。
记录错误堆栈信息
WARN
警告:指明可能潜在的危险状况。
记录运维过程报警数据
INFO
信息:指明描述信息,从粗粒度上描述了应用运行过程。
记录运维过程数据
DEBUG
调试:指明细致的事件信息,对调试应用最有用。
程序员调试代码使用
TRACE
跟踪:指明程序运行轨迹,比DEBUG级别的粒度更细。
运行堆栈信息,使用率低
ALL
所有:所有日志级别,包括定制级别
ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF
设置日志组,控制指定包对应的日志输出级别,也可以直接控制指定包对应的日志输出级别
debug: true logging: level: root: debug spring: main: banner-mode: off
日志文件
logging: file: name: server.log logback: rollingpolicy: max-file-size: 3KB file-name-pattern: server.%d{yyyy-MM-dd}.%i.log
日志输出格式控制
logging: pattern: console: "%d %clr(%p) --- [%16t] %clr(%-40.40c){cyan} : %m %n"
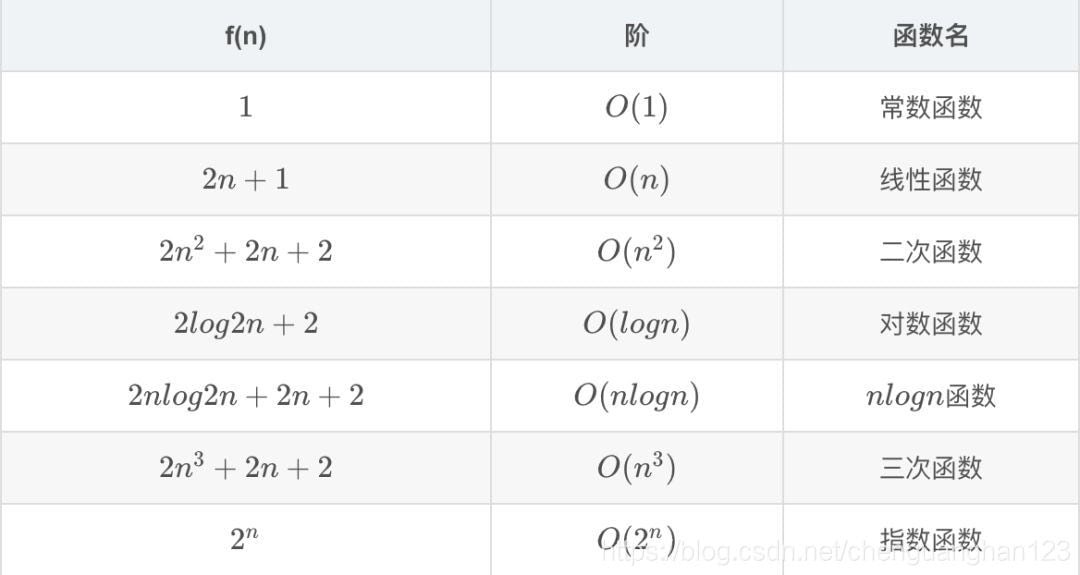
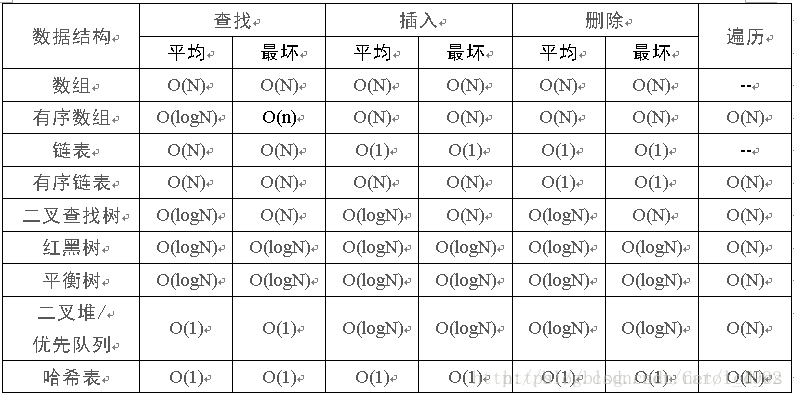
时间复杂度
在上图中,我们可以看到当 n 很小时,函数之间不易区分,很难说谁处于主导地位,但是当 n 增大时,我们就能看到很明显的区别,谁是老大一目了然:
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n)
出处:https://blog.csdn.net/chenguanghan123/article/details/83478259
如果ax=N(a>0,且a≠1),那么数x叫做以a为底N的对数,记作x=logaN,读作以a为底N的对数,其中a叫做对数的底数,N叫做真数。
出处:https://blog.csdn.net/ted_cs/article/details/82881831
Java正则表达式 https://www.runoob.com/regexp/regexp-syntax.html
字符类 [abc] a 、b 或 c (简单类)[^abc] 任何字符,除了 a 、b 或 c (否定)[a-zA-Z] a 到 z 或 A 到 Z ,两头的字母包括在内(范围)[a-d[m-p] ] a 到 d 或 m 到 p :[a-dm-p] (并集)[a-z&&[def23] ] d 、e 或 f (交集)[a-z&&[^bc] ] a 到 z ,除了 b 和 c :[ad-z] (减去)[a-z&&[^m-p] ] a 到 z ,而非 m 到 p :[a-lq-z] (减去)预定义字符类 . 任何字符 \d 数字:[0-9] \D 非数字: [^0-9] \s 空白字符:[ \t\n\x0B\f\r] \S 非空白字符:[^\s] \w 单词字符:[a-zA-Z_0-9] \W 非单词字符:[^\w] 以上正则匹配只能校验单个字符。 Greedy 数量词X ? X ,一次或一次也没有X * X ,零次或多次X + X ,一次或多次X {n } X ,恰好 n 次X {n ,} X ,至少 n 次X {n ,m } X ,至少 n 次,但是不超过 m 次public String [] split (String regex);public String replaceAll (String regex,String newStr);
正则表达式爬取信息中的内容 。
public class RegexDemo05 { public static void main (String [] args ) { String rs = "来黑马程序学习java,电话020-43422424,或者联系邮箱" + "itcast@itcast.cn,电话18762832633,0203232323" + "邮箱bozai@itcast.cn,400-100-3233 ,4001003232" ; String regex = "(\\ w{1,}@\\ w{2,10}(\\ .\\ w{2,10}){1,2})|(1[3-9]\\ d{9})|(0\\ d{2,5}-?\\ d{5,15})|400-?\\ d{3,8}-?\\ d{3,8}" ; Pattern pattern = Pattern .compile (regex ); Matcher matcher = pattern .matcher (rs ); while (matcher .find ()){ System .out .println (matcher .group ()); } } }
Java定时任务 private static void timerTask () throws InterruptedException { Timer timer = new Timer (); TimerTask timerTask = new TimerTask () { @Override public void run () { System.out.println("hi, 欢迎关注:java技术栈" ); } }; long delay = 2000 ; long period = 3 * 1000 ; timer.schedule(timerTask, delay, period); Thread.sleep(20000 ); timer.cancel(); timer.purge(); }
并发编程 多线程 程序是静止的,运行中的程序就是进程。 进程的三个特征: 1 .动态性 : 进程是运行中的程序,要动态的占用内存,CPU 和网络等资源。2 .独立性 : 进程与进程之间是相互独立的,彼此有自己的独立内存区域。3 .并发性 : 假如CPU 是单核,同一个时刻其实内存中只有一个进程在被执行。CPU 会分时轮询切换依次为每个进程服务,因为切换的速度非常快,给我们的感觉这些进程在同时执行,这就是并发性。
什么是线程? 线程是属于进程的。一个进程可以包含多个线程,这就是多线程。 线程是进程中的一个独立执行单元。 线程创建开销相对于进程来说比较小。 线程也支持“并发性”。
线程的创建方式 a .继承Thread类的方式 -- 1 .定义一个线程类继承Thread类。 -- 2 .重写run ()方法 -- 3 .创建一个新的线程对象。 -- 4 .调用线程对象的start ()方法启动线程。 注意: 1 .线程的启动必须调用start ()方法。否则当成普通类处理。-- 如果线程直接调用run ()方法,相当于变成了普通类的执行,此时将只有主线程在执行他们! -- start ()方法底层其实是给CPU注册当前线程,并且触发run ()方法执行 2 .建议线程先创建子线程,主线程的任务放在之后。否则主线程永远是先执行完!
Thread t = new MyThread ();t.start() class MyThread extends Thread { @Override public void run () { for (int i = 0 ; i < 100 ; i++ ){ System.out.println("子线程输出:" +i); } } }
Thread类的API 1. public void setName (String name) :给当前线程取名字。2. public void getName () :获取当前线程的名字。-- 线程存在默认名称,子线程的默认名称是:Thread-索引。 -- 主线程的默认名称就是:main 3. public static Thread currentThread () -- 获取当前线程对象,这个代码在哪个线程中,就得到哪个线程对象。 4. public static void sleep (long time) : 让当前线程休眠多少毫秒再继续执行。-- public Thread () -- public Thread (String name) :创建线程对象并取名字。
b.实现Runnable接口的方式。 Thread的构造器: 实现Runnable接口创建线程的优缺点: 缺点:代码复杂一点。 优点: 注意:其实Thread类本身也是实现了Runnable接口的。
Runnable target = new MyRunnable ();Thread t = new Thread (target);t.start(); class MyRunnable implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++ ){ System.out.println(Thread.currentThread().getName()+"==>" +i); } } } new Thread (new Runnable () { @Override public void run () { for (int i = 0 ; i < 10 ; i++ ){ System.out.println(Thread.currentThread().getName()+"==>" +i); } } }).start();
c.线程的创建方式三: 实现Callable接口。 优点:全是优点。 缺点:编码复杂。
Callable call = new MyCallable ();FutureTask<String> task = new FutureTask <>(call); Thread t = new Thread (task);t.start(); try { String rs = task.get(); System.out.println(rs); } catch (Exception e) { e.printStackTrace(); } class MyCallable implements Callable <String>{ @Override public String call () throws Exception { int sum = 0 ; for (int i = 1 ; i <= 10 ; i++ ){ System.out.println(Thread.currentThread().getName()+" => " + i); sum+=i; } return Thread.currentThread().getName()+"执行的结果是:" +sum; } }
线程同步_同步代码块 线程同步的方式有三种:
a.同步代码块。 synchronized (锁对象){} 锁对象:理论上可以是任意的“唯一”对象即可。 原则上:锁对象建议使用共享资源。 -- 在实例方法中建议用this 作为锁对象。此时this 正好是共享资源!必须代码高度面向对象 -- 在静态方法中建议用类名.class字节码作为锁对象。
b.同步方法 方法加上一个修饰符 synchronized . public synchronized void drawMoney (double money) :同步方法其实底层也是有锁对象的: 如果方法是实例方法:同步方法默认用this 作为的锁对象。 如果方法是静态方法:同步方法默认用类名.class作为的锁对象。
c.lock显示锁。 java.util.concurrent.locks.Lock机制提供了比synchronized 代码块和synchronized 方法更广泛的锁定操作, 同步代码块/同步方法具有的功能Lock都有,除此之外更强大 Lock锁也称同步锁,加锁与释放锁方法化了,如下: - `public void lock () `:加同步锁。 - `public void unlock () `:释放同步锁。
public void drawMoney (double money) { String name = Thread.currentThread().getName(); lock.lock(); try { }catch (Exception e){ e.printStackTrace(); }finally { lock.unlock(); } }
字符集/编码集 1B = 8b 计算机中的最小单位是字节B.
一个字节8 位,2 ^8 = 256 位 ASCII 编码:ASCII它是一种7 位编码,但它存放时必须占全一个字节,也即占用8 位。a 97 b 98 A 65 B 66 0 48 1 49 GBK 编码:2 个字节Unicode 编码(万国码):UTF -8 :3 个字节英文和数字在任何编码集中都是一样的,都占1 个字节。 英文和数字在任何编码集中可以通用,不会乱码!! GBK 编码中,1 个中文字符一般占2 个字节。UTF -8 编码中,1 个中文字符一般占3 个字节。
泛型 泛型接口
修饰符 interface 接口名称<泛型变量> }
public interface Data <E> { void add (E stu) ; void delete (E stu) ; void update (E stu) ; E query (int id) ; } public class StudentData implements Data <Student> { @Override public void add (Student stu) { System.out.println("添加学生!" ); } @Override public void delete (Student stu) { System.out.println("删除学生!" ); } @Override public void update (Student stu) { } @Override public Student query (int id) { return null ; } }
泛型通配符
通配符:? ?可 以用在使用泛型的时候代表一切类型。E , T , K , V是在定义泛型的时候使用代表一切类型。 泛型的上下限: ? extends Car : 那么?必 须是Car或者其子类。(泛型的上限) ? super Car : 那么?必 须是Car或者其父类。(泛型的下限。不是很常见)
public class GenericDemo { public static void main (String[] args) { ArrayList<BMW> bmws = new ArrayList <>(); bmws.add(new BMW ()); bmws.add(new BMW ()); bmws.add(new BMW ()); run(bmws); ArrayList<BENZ> benzs = new ArrayList <>(); benzs.add(new BENZ ()); benzs.add(new BENZ ()); benzs.add(new BENZ ()); run(benzs); ArrayList<Dog> dogs = new ArrayList <>(); dogs.add(new Dog ()); dogs.add(new Dog ()); dogs.add(new Dog ()); } public static void run (ArrayList<? extends Car> cars) { } } class Car {} class BMW extends Car {} class BENZ extends Car {} class Dog {}
自定义泛型方法
修饰符 <泛型变量> 返回值类型 方法名称(形参列表){ }
class class1 { public static <T> String arrToString (T[] nums) { StringBuilder sb = new StringBuilder (); sb.append("[" ); if (nums != null && nums.length > 0 ) { for (int i = 0 ; i < nums.length; i++) { T ele = nums[i]; sb.append(i == nums.length - 1 ? ele : ele + ", " ); } } sb.append("]" ); return sb.toString(); } }
自定义泛型类
修饰符 class 类名<泛型变量>{ } 泛型变量建议使用 E , T , K , V
class MyArrayList <E> { private ArrayList lists = new ArrayList (); public void add (E e) { lists.add(e); } public void remove (E e) { lists.remove(e); } @Override public String toString () { return lists.toString(); } }
Java语言-相关书籍
Java语言-资源
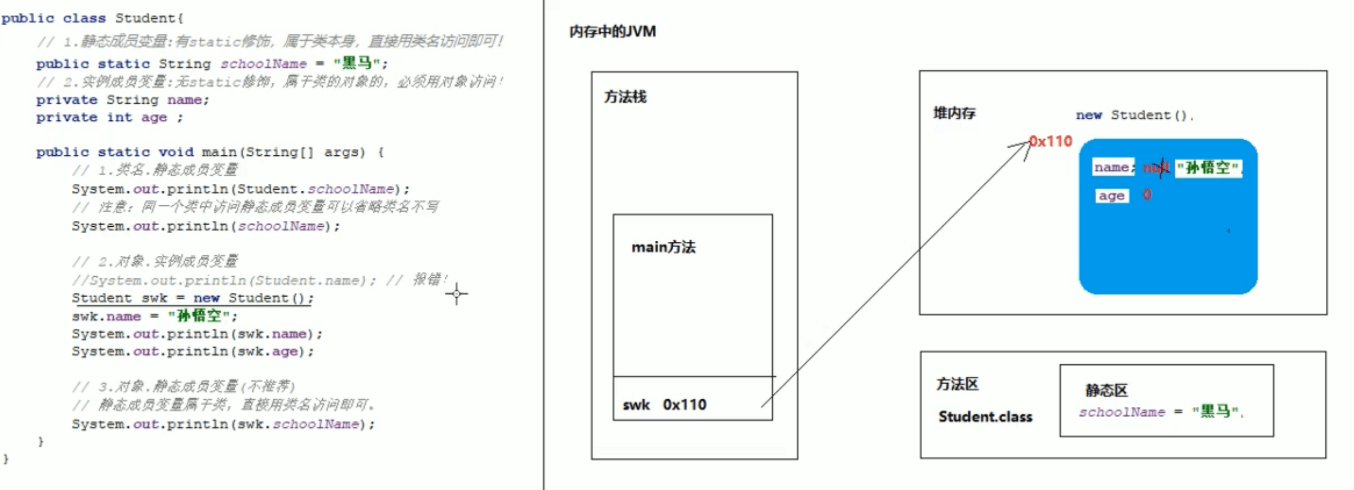
临时笔记
推荐:优先使用不可变的类 LocalDate
不推荐使用:Switch语句 goto语句 char类型 int i, j
Character类的 isJavaIdentifierStart isJavaIdentifierPart
15/2 = 7 15%2 = 1 15.0/2 = 7.5
strictfp
Math.sprt(x) 平方根
StrictMath类 得到一个完全可预测的结果,速度比Math差
int[ ] arrs2= Arrays.copyof(arrs1,arrs1.length)
依赖 uses-a
jdeprscan 工具类(检测代码中是否使用用已经废弃的API)
Objects.requireNonNullElse(n,”unknow”)
值传递、引用传递
SELECT DISTINCT vend_id FROM products
DESC关键字只应用到直接位于其前面的列名
SQL优先处理AND操作符
IN操作符一般比OR操作符清单执行更快
cat 1.txt 查看文件内容
ResultFul
restful资源设计
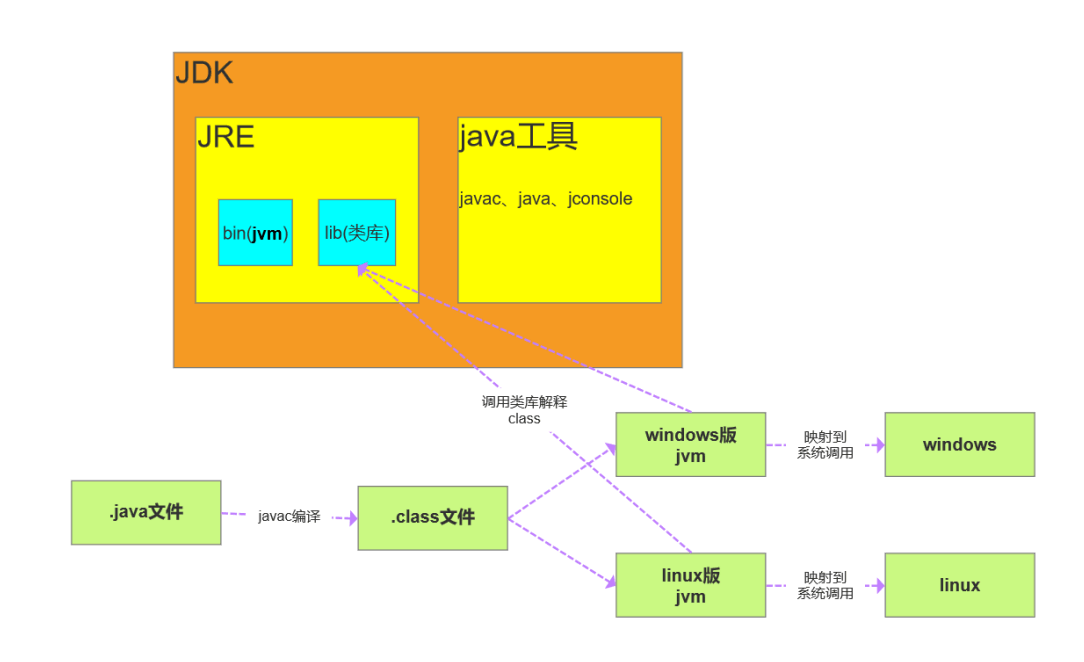
JDK JRE JVM
JDK:java Develpment Kit java 开发工具
JRE:java Runtime Environment java运行时环境
JVM:java Virtual Machine java 虚拟机